Concept¶
Isilon clusters consist of three to hundreds of individual nodes which can connect independently to a Local Area Network. For each Isilon cluster, a single file system is represented through a multitude of protocols through every cluster node connected to the network.
Consequently, there is an individual network address for each node in a cluster. Typically, these addresses are arranged in one or more address ranges, spanning a certain part of an IP subnet. In order to balance incoming and outgoing traffic to and from the single file system provided by the cluster across all of its nodes, a distributed DNS server mechanism available from EMC (Isilon SmartConnect Advanced) cycles through the addresses providing access to said file system based on data such as the number of active connections per node and load statistics or in a simple, round-robin fashion.
Every computer about to connect to an Isilon cluster based on DNS name resolution will receive an individual node’s IP address and thus load balancing according to the prevailing algorithm is being served. However, since mounting the Isilon file system via NFS is the only supported way for a ISP server to use Isilon storage for a storage pool, such load balancing would occur only once when the file system is mounted. All subsequent access to data would then be routed through the Isilon node originally addressed by SmartConnect at the very moment the NFS mount took place. Every ISP server connected to an Isilon cluster would only be able to use a fraction of the theoretical throughput provided by this cluster at any given time.
Load balancing through ISP’s device class definitions (i.e., addressing the Isilon file system via more than one individual NFS mounts) could utilize more bandwidth but it would have several drawbacks. First, addressing the same file system through more than one mount point would undermine ISP’s internal capacity calculations because ISP would assume the free space reported for each mount point to be genuine and henceforth sum them up to a multiple of free space actually available.
Secondly, ISP addresses each volume of data via the exact path it took when the volume was initially created. So, any data written to a volume on path “a” can only be read and added to on that same path “a”, which undermines load balancing and effectively leads to heavily unbalanced utilizations of possible paths when previously written data is being read.
dsmISI provides a simple yet effective way to address all nodes of a virtually unlimited number of Isilon clusters from a virtually unlimited number of ISP servers in a balanced way without having to handle complex NFS mount structures or ISP device class definitions by:
mounting all nodes associated with an Isilon cluster via NFS to the operating system it is running on.
automatically adding Isilon cluster nodes once they have been installed.
providing the ISP administrator with a single target directory for one or more device classes.
balancing ISP read and write workloads effectively across all nodes of an Isilon cluster.
Access Zones¶
To provide additional security to the ISILON cluster and minimize unnecessary access via ssh, dsmISI supports the usage of Access Zones.
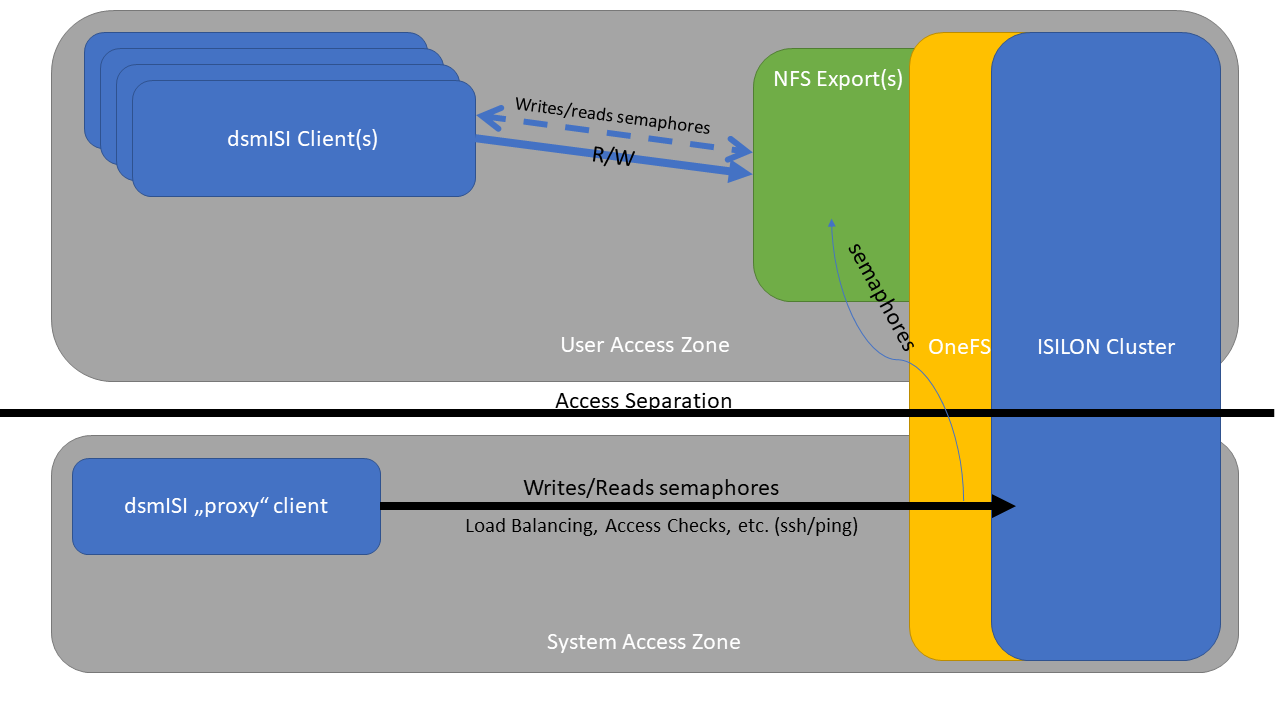
Logical overview for separated Zones with dsmISI.¶
In order to accomplish dsmISI functionality with separated zones, one “Proxy” client has to be configured, which has access to the system zone of the ISILON cluster. Then, all other dsmISI client systems which want to access that ISILON do only have to be configured with the “IsiDataIP”
dsmISI Snapshot¶
Data loss poses serious threats to any organization and mitigating its impact is the major reason for backups to be done in the first place.
Historically, data loss was caused by hardware and software failure, big and small environmental disasters or user mishaps and performing regular backups became best practice to turn back the clock and restore information to whatever the latest backed up version was.
With the rise of cyber criminality, the scope of backups has changed. No longer is it sufficient to do backups and keep them in locations physically and logically separated from their source. Backups now have to cope with the possibility of being directly targeted by malicious software and/or users with the sole aim of destroying them in order to prevent recovery.
Caution
Whether primary data has been encrypted in order to capture ransom or deleted in order to bankrupt the owner doesn’t matter in this context. Backups would mitigate any such scenario - apart from data theft - and backup data is therefore targeted with the highest priority.
While it is important for ransomware attackers to keep primary data intact but unaccessible, no such subtleties are required for backup data. Once primary data has been encrypted, backup data is simply destroyed. Destroying data is typically much faster than encrypting it as long as the devices holding that data are accessible. Dumping just a few bytes of random data directly across disk devices, for example, will usually do the trick - even if the file system installed on top of these devices provides sophisticated tools and methods to prevent unauthorized access or logical snapshots to “undo” such attacks if they would play nice and happen on the file system layer.
For protection from a scenario in which an attacker gained privileged access to a backup system, the layer providing suitable functionality for protecting the data must reside out of reach for any of the backup system’s devices or accessible resources in general. It is also vitally important to enable separation of responsibilities and access for handling backup data from handling its protection. On the other hand, backup data has to be protected in ways closely coordinated with the backup infrastructure. It wouldn’t make sense to protect, for example, a particular point in time of a Spectrum Protect storage pool while the database holding all relevant mata information for that data hasn’t been backed up yet. Just like it would be folly to protect a XFS file system used by Veeam as a backup repository without making sure it is consistent and recoverable in its entirety.
dsmISI makes sure that backup data remains protected even if privileged access to a backup server has been gained by a malicious attacker. This is achieved by strictly separating the function requesting a persistent snapshot running on the backup server from the function actually interacting with the snapshot function on PowerScale storage. At all times, only the PowerScale System Zone has access to snapshot data and only from that zone, snapshots can be deleted or interfered with in any other way. Additionally, dsmISI manages snapshots of multi-purpose, auxiliary data shares and exports which can be used from applications and users outside of the scope of backup applications which are still vital for a full recovery from scratch. This may include documentation files, operating system backups, boot media images and other meta information that would be required to get an infrastructure running from a complete cold start.
Note
Always make sure to follow Recommendations by Dell regarding Snapshots
Snapshots and Access Zones¶
Like with dsmISI, to separate the ISILON System Zone and thus a vulnerable point for possible attacks, dsmISI snapshot functionality works with separated Access Zones. In order to accomplish this separation, one single dsmISI System has to have access to the system zone and will function as the Snapshot Creator while all other dsmISI systems can be configured to only have access to their designated access zones.
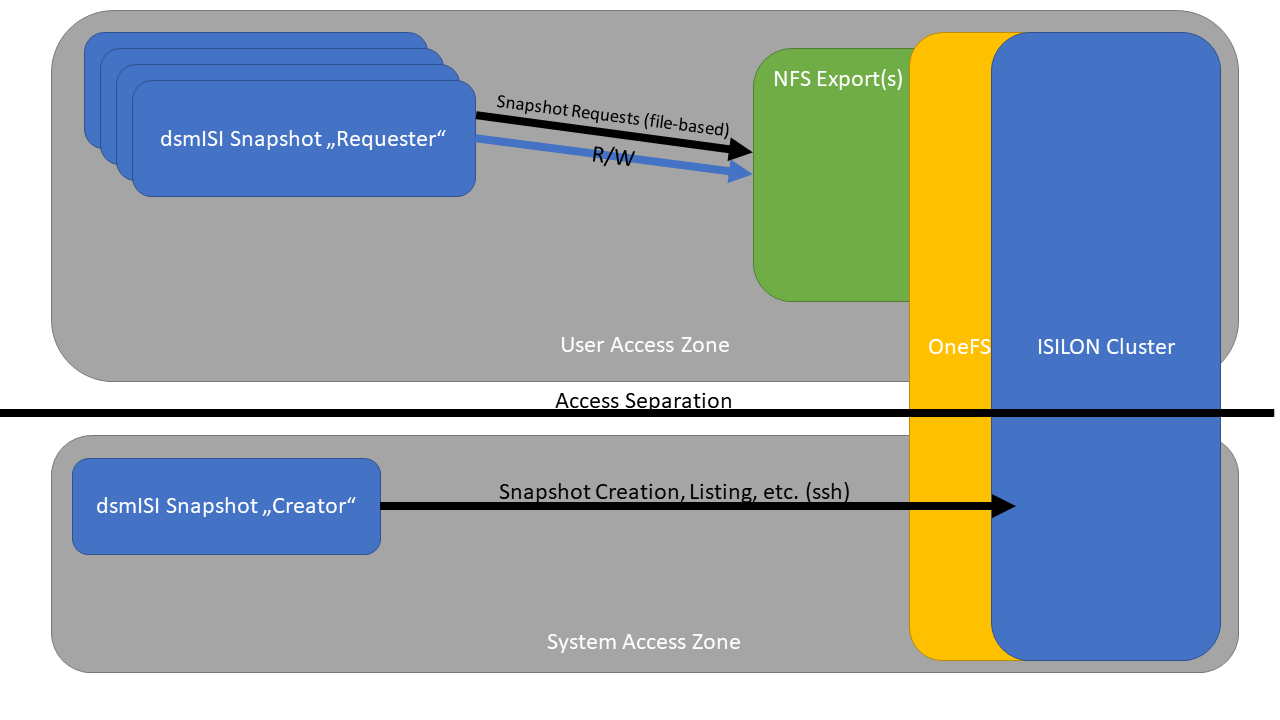
Logical overview for separated Zones with dsmISI Snapshot.¶