Configuration
This chapter describes the GSCC architecture and its configuration. For a better understanding of the configuration, it is important to first define and explain terms that will be used in GSCC installations. In addition to the GSCC terminology, it is also crucial to understand the basic logic of the cluster. The logic of the cluster is based on a so-called state model. This chapter therefore explains the background and function of the state model and also the different possible states and their dependencies. Furthermore it is outlined how the state model can be configured differently to adjust the cluster’s behavior. All this are the basics for understanding and working with the cluster.
Terminology
This section explains and defines important GSCC terms in order to make it easier to understand the concept and the architecture. The figure below shows a configuration overview and additionally illustrates some of the terms used for a cluster environment.
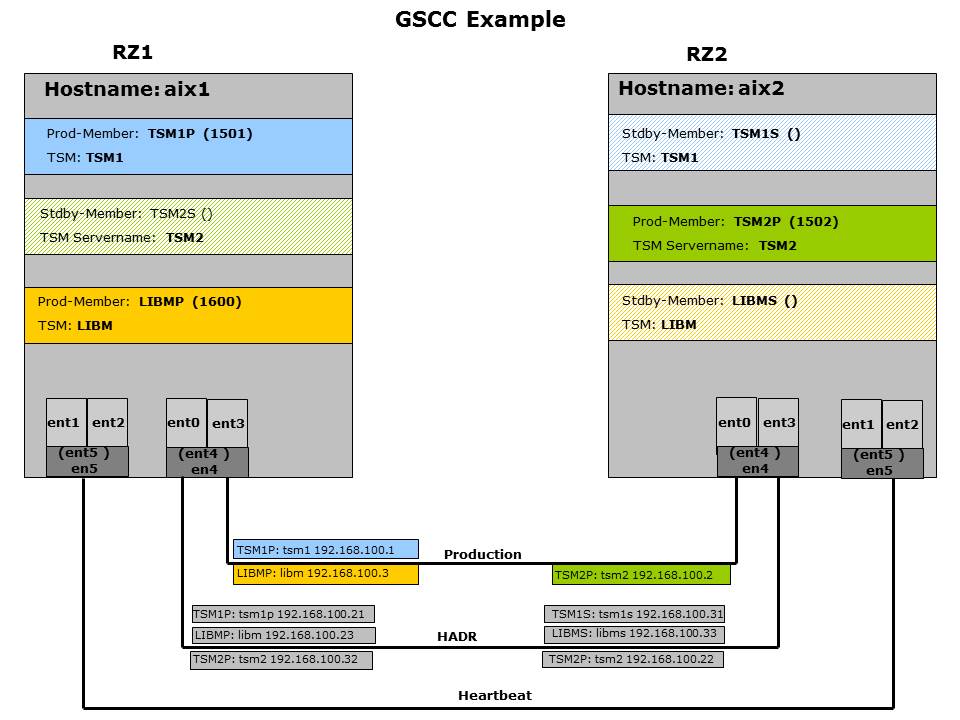
GSCC Production and Standby member
Here is a list of typical terms used to describe a GSCC cluster setup.
Host / UNIX System
The physical UNIX servers which are member of the cluster configuration are called hosts or simply UNIX systems in this document. A GSCC cluster mostly consists of two physical hosts.
ISP Servername / Instance
ISP server name is the name which was set within ISP. Actually it is better to use the term ISP instance instead as it makes it easier to differentiate between an ISP server and the UNIX server or system it is running on. ISP server refers to the ISP instance throughout this document. The UNIX server is referred as system. In normal operation the ISP instances are activated on a certain system.
aix1 aix2
---------------------------------------------
LIBM ISP2
ISP1
In the cluster setup the ISP instance can also be activated on the opposite system and even on a database copy (standby). GSCC handles the ISP instance configurations and prepares all necessary steps to activate the ISP instance, no matter if this is on the primary or a standby database.
ISP Standby Instance
Technically the Standby instance is an independent prepared ISP server instance with dedicated resources for log and database usually on the remote system to be available as copy of a productive ISP instance. In theory this ISP instance could be activated in parallel with the productive primary ISP instance. However, the database is only a copy of the primary and shares resources like storage pools and service IP addresses. GSCC supports only High Availability Disaster Recovery (HADR) based synchronization DB2 HADR function provides a solid log shipping mechanism which is used with GSCC to provide a standby copy of the database.
DB2 Instance
As ISP is closely coupled with DB2 it appears that an ISP instance always relates to a DB2 instance. In a cluster environment (not only GSCC) this is technically not the case. Even in a pure server based cluster there is a separate DB2 instance on each system for a single ISP instance. Especially in a GSCC configuration with HADR involved the differentiation is crucial.
ISP Instance / GSCC Member DB2 Instance
--------------------------------------------------------------------------
ISP1P isp1p
ISP1S isp1s
DB2 HADR
DB2 instances can be configured to be highly available with the “High Availability Disaster Recovery” (HADR) functionality. This functionality is used with GSCC. More information on how it works is available at the IBM documentation for DB2 HADR.
Note
The different roles an HADR enabled DB2 instance can have are represented by the GSCC Roles
ISP Resources
GSCC is managing different ISP resources These resources can be devided into these groups:
- ISP Home Disk Resources
Depending on cluster setup these resources can be configured on a shared SAN device or locally. * Home filesystem with ISP option file (dsmserv.opt), device configuration, volume history, dsmserv.dsk (only ISP5) – also referred to as ISP config directory * DB2 instance home - optional also in ISP home directory * ISP database volumes and filesystems * ISP log volumes (active log, archive log, mirror log, failover log)
- ISP DB2 HADR Resources
Depending on cluster setup these resources can be configured on a shared SAN device or locally. * HADR “Primary” IP-address * HADR “Standby” IP-address * DB2 database HADR
- ISP Storage Pool Resources (optional)
Filesystems and/or raw devices for ISP disk and/or file storage pools
SAN based filesystems
GPFS filesystems
NFS filesystems
NFS/dsmISI ISILON filesystems
- ISP Server Process
Starting and Stopping ISP instances
ISP instances can be moved between the servers
- IP Addresses of the ISP Instance
The service and management addresses can be moved between the systems together with the ISP instance (see also Service IP)
HomeVG
This term is used to describe the disk or volume group including the filesystems for the ISP configuration, database and logs. It is usually a shared resource which can be moved between the UNIX systems. When HADR is used there is a HomeVG for the primary and one HomeVG for the standby instance. Both can be moved between the systems independently.
Home Filesystem / Config Filesystem
Within the HomeVG mostly a dedicated filesystem is defined for the ISP configuration files like dsmserv.opt, device config, but also for the key database and the volume history. This filesystem is called the ISP “home” or the “config” filesystem. The ISP home filesystem is not necessarily the home filesystem of the ISP user or the db2 home filesystem. The usage of this filesystem is explained in more detailed in the upcoming sections.
Storage Pool VG (stgVG)
The ISP disk resources are separated from the database resources in a GSCC cluster environment. As described before the database, logs and configuration information are placed in the homeVG. The disk storage pool resources are summarized as stgVG. The separation is necessary as the stgVG is a shared resource that must be able to be activated together with the primary homeVG or standby homeVG as required. The only exception is GPFS in this case as it is available on both hosts anyway.
Home System
The home system is defined for each GSCC member (ISP Instance) and refers to the host ID of the UNIX. In normal operation the ISP Instance is activated on the home system.
DB2 UNIX User
Every DB2 instance is running under a separate UNIX user, usually with the same name as the instance. When using primary and standby databases, it is recommended to also use different users, when the databases are also shared in the SAN.
Targetserver
Target server is the term for the ISP Server to which an ISP sends its database backup utilizing server-to-server communication. This is only used for Classic Sync clusters.
Base IP
Each network interface needs a fix IP address which is not changed. This is referred as the base address for the specific interface. At least two interfaces with base addresses are usually configured, management and client interface.
Service IP / Production IP
A Service IP address is an address, which is used by ISP clients and storage agent for backup communication. In a cluster setup it must be possible to move this address together with the ISP instance to another system. These addresses are configured as IP aliases on the base IPs and are being controlled by GSCC.
ISP Server Networkname Netzworkaddress
------------------------------------------------------------
LIBM libm.net.de 192.168.100.3
ISP1 isp1.net.de 192.168.100.1
ISP2 isp2.net.de 192.168.100.2
Admin IP / Management IP
In a GSCC configuration multiple IP addresses can be configured. It is recommended to use a dedicated network for administration of GSCC. This is referred as admin IP or management IP. This network is usually also used for ISP administration. The management IP for ISP must also be a virtual address not bound to any interface. GSCC will move this alias between the system on top of the interface’s base IP. The management network should not be used for HADR communication, if performance for the log shipping is not sufficient.
Heartbeat IP
In a GSCC configuration it is strongly recommended to provide a dedicated heartbeat network between the two servers additionally to the administrative and productive network. The heartbeat is configured as IP addresses and is beside the dedicated heartbeat connection also configured across all other network interfaces.
HADR Primary / Standby IP
With GSCC and HADR primary and standby databases can be moved between UNIX systems independently from each other. For this reason it is necessary to also provide system independent IP addresses for HADR. GSCC is using also IP aliases to control the HADR communication. In HADR only cluster, these alias addresses are not required.
GSCC State Model
GSCC architecture is based on a state model, where different inputs result into a certain state. This new state optionally has an action defined which to perform in this situation and it has further inputs defined to decide on the next state. These states are not related to the cluster, a single ISP instance or a system but for a certain cluster object managing an ISP instance. The object definitions are called cluster member. So each member has a certain state based on the input. On important input for GSCC is thereby the status of other members managing the same ISP instance. There are two levels of states, local and global states. The global states are shared with the other members.
GSCC Member
As GSCC is an application cluster the configuration, working units and state information refer always to ISP rather than to a UNIX system. GSCC is working with objects in order to control the different resources for an ISP server. The resources and definitions for the different database instances for an ISP server are organized in members. A member will always have certain state, which is also communicate to the other members. In a simple shared disk setup there are two members for an ISP server, one per ISP system. In an advanced HADR cluster with additional standby resources there are 4 members for an ISP server. The members used to control a single ISP server are forming a member team.
ISP Instanz GSCC-Member GSCC-Member Home System
Produktion Standby
-------------------------------------------------------------------------
LIBM LIBMP LIBMS aix1
ISP1 ISP1P ISP1S aix1
ISP2 ISP2P ISP2S aix2
GSCC Member Team
This is an example for a member team defined for ISP instance LIBM. Within the member team the state of the other members are checked regularly.
aix1:LIBMP aix2:LIBMP
aix1:LIBMS aix2:LIBMS
- There are two communication ways:
Communicate with a partner member
Communicate with a peer member
The different communication ways are described in the following abstracts.
Partner Member
Partner member are the two members managing the same resources group (homeVG), but on different hosts. In a simple shared disk only cluster setup for an ISP instance this means the resource is either activated on one host or the others. One member must control the resource and is communicating this to the partner member. In case the member in control cannot keep the resource up, the partner member is in charge. Even a standby database is controlled by a member that needs a partner member in case this resource is also on a shared disk. Just like the primary the standby homeVG can be activated on both hosts. Actually there is no real difference between a primary and a standby member as every member can take any role in the member team.
Peer Member
The partner member relationship defines which partner is currently active. The activated member then takes a role as primary or as a standby member by communicating with the peer member. The peer member only exists when there is a primary/standby configuration. In case of a pure HADR cluster there is only peer communication as the homeVGs are local and need not to be managed separately.
GSCC Operator Mode/State
The GSCC cluster can be switched into a passive mode to be able to perform maintenance work with ISP, restart GSCC components or use the CLI or GUI to activate or deactivate the ISP instance. This mode is called Operator Mode. The operator mode is requested for the member of an ISP member team and as soon as all members are changed to the cluster state “Operator” the Operator Mode is established and maintenance work can be performed. In Operator Mode the cluster is not reacting on any changes to the system or ISP. The Operator Mode is always recommended when changes are performed on the hosts like reboot, network reconfiguration or disk reconfiguration. Furthermore the Operator Mode provides Operator Commands to manage the ISP servers. You can stop ISP, start ISP or switch ISP to the other host, while in Operator Mode. If the cluster should be activated again the cluster command “Join” was be performed on all members of a member team. GSCC will check the ISP and its resources to decide on the current member states. Then the cluster is activated again.
GSCC Roles
Each ISP instance in a GSCC cluster is represented by one of the following roles:
Primary
This is the role for an active site in a GSCC cluster. When starting the cluster services, this system will start the DB2 as primary and the ISP instance per default.
Standby
This is the role for the passive system in a GSCC cluster. When starting the cluster services, this system will activate in standby mode to receive changes in the primary systems DB2 and not start the ISP instance. When the Primary system fails, this site will try a takeover.
Standard
This is the role for a standalone ISP instance not configured for DB2 HADR/Clustering. In a GSCC environment, this can be the case when one of the clusters systems fails: The working site will then stop the DB2 HADR/Clustering mode and start as a “standalone” system for as long as the other site is unavailable.
Trigger
The term “Trigger” is used for a special confirmation button or command in situation where automation was not activated and the Operator wants to confirm an action manually. In certain cases a failover should not be performed automatically, but as soon as the Operator decides to start the failover only the trigger needs to be used to start the automatic process of moving resources. This would be considered an active trigger. A trigger can also be passive. This is a situation where the trigger does not decide on an action, but just confirms a certain state (ISP server has Failed).
Sync / Peer
Sync is the expression used for the synchronization for the ISP database as described before. Usually it was also used to define the database status where the databases are in “sync”. When using HADR the technically better term is “peer” as it is used by DB2 for the clean synchronized status.
State Model
The logic of the GSCC is based on a so-called State Model. A state model uses inputs to determine a certain state. Each state can optionally start an action, if the state requires this, and then collect further input. Depending on the input results the state is changed again and so on. There is always a state change happening. If no exceptions occur, a regular cycle is stepped through. GSCC is exactly doing this with ISP. One cycle would be to check the status of the productive ISP instance. Different states are checking different resources like is the process still there, is it possible to logon etc. So these checks are performed regularly in a cycle. If now an exception would occur and one input would differ, another state would be reached and cycle will be left. A simple example could be a crashed ISP instance where the input about the ISP process returns that no ISP process is active. This would lead to another state, where an action is needed. So in this state the action “startISP” would be executed and the result would be checked again and so on.
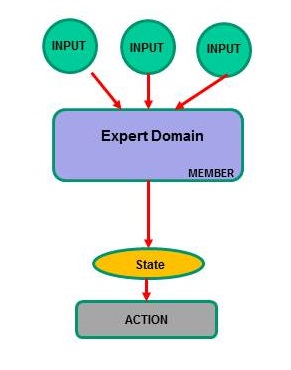
State model
GSCC is using interacting objects to manage an ISP instance. The object is represented by a so called member. Each member is cycling to the state model. Depending on the failover configuration there can be up to 4 members per ISP instance. In the following example an ISP server “ISP1” is clustered with shared disk resources and HADR using a primary and a standby database. As there are two hosts in the cluster, the member team is built by four members. Each member can take any state and role in this setup. While each member cycles through the different states one important input is the state of the other members. If for example the disk resource for the primary DB for ISP1 is activated on host “aix1”, it must not be activated on “aix2”. The same is valid for the standby database disk resources. Furthermore a decision must be taken between the members controlling the activated disk resources, who is primary and who is standby. Although the names were chosen to reflect a certain role, the state model allows all members to take all roles.
aix1:ISP1P aix2:ISP1P
aix1:ISP1S aix2:ISP1S
The different states, a member is cycling through, is first of all a local state. A local state is not visible to the other members and also not to the administrator (of course for analysis) viewing the cluster status. Certain states within the cycle are visible to the other members and the administrator. These are “Global States”. The global states allow the members to react on the state of another member (ISP has “Failed” for the other member, so this member needs to take action). The global state is also visible in the GUI to the administrator to see the overall cluster status. Therefore it is important to understand the meaning of the global states.
Cluster States
Following up are the most important global states.
Up
This member is controlling the productive ISP server and actions are performed to start ISP. “Up” is a cycle to check the ISP status regularly.
Available
This member takes care of the standby database and takes action in case HADR is not in “peer” status or the classic sync was not performed. “Available” is also a cycle to check the standby status regularly.
Inactive
The member is completely inactive, no actions are performed. The homeVG is offline on this member’s host.
Down
The member is in a transition state. In this state the homeVG is activated or when just entered will be activated. With HADR also the HADR IP addresses are set. Then the status of the peer member is checked to decide about the primary or standby role. The next global state would then be either “Up” or “Available”.
Failed
The member has a major problem and this member indicates with this state to the peer member that a standby failover is needed. If the peer member is capable to take over the needed action is performed.
Broken
The member could not fulfill the global state “Up” and gives up. All resources are cleaned up and removed indicating the partner member to take over.
Operator
In the Operator state the cluster is deactivated. The Operator can use GSCC commands to manage the ISP instances. This status is persistent even through restart of the GSCC daemons or a reboot.
Join
Whenever a cluster status is unknown (i.e. after a reboot or when leaving Operator Mode) the “Join” state is used and the current member situations are verified. The member would only continue if all members in a member team are in this state first.
Unknown
Unknown is not a real defined state in the state model. It is a placeholder for situation, when no state could be determined by the input methods. This is possible after a system reboot, while not being in Operator or if the state model has an error or an input method returned an invalid value. This would be considered as a bug.
Cluster Behaviour
“Up” and “Available” are stable states, which are part of the main cycles of the state model. In the “Up” cycle the active ISP server is checked and kept running, while the “Available” state is controlling the DB2 standby database or the synchronized database (classic sync). This means that in a normal cluster situation these global states are not changing. Only these global states are visible to the other members, but in the background the state model and expert engine is still cycling to different local states. These local states represent a number of checks and if necessary an action if required. As long as the global state can be hold (even if an ISP restart is needed for that) the global state will not change. The members in “Up” and “Available” for the same ISP instance are called peer members (Fig. 4, ISP11P and ISP11S). Whenever there are shared disks used in the cluster which can be activated on both sides one further stable state is visible: “inactive”. If any member is active on one side, it needs to be inactive on the other side. These two members are called partner members (Fig. 4, ISP11P in RZ1 and ISP11P in RZ2).
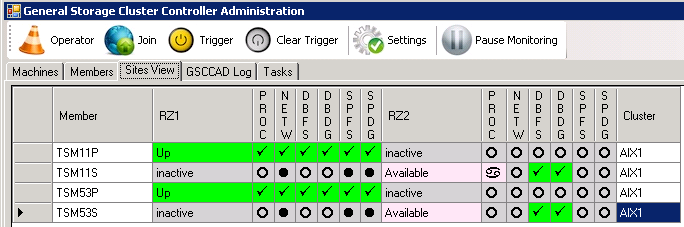
Production and Standby - normal status
“Failed”, “Broken” and “Operator are also important global states. They are passive and stable states, they basically only wait for some external input to react again or to leave to another state. “Failed” and “Broken” are error states which perform cleanups, but mostly make the problem visible to partner or peer members. If the error which caused the status is resolved, the operator can request to switch to the “Operator” state, from which a join and activation of this resource is possible again. While a member is in “Operator”-state (the member team will follow, so Operator Mode is on) it can receive commands as input. Commands are used to control ISP instances and its resources. The “join” command allows to leave the “Operator”-state. All other global states are transition states. They also inform the other members in the member team about the current activities but only actions are performed to prepare a status change to one of the stable global states. Good examples are “Join” and “Down”.
The state “Unknown” is an exception. “Unknown” is not a defined state in the cluster. It will not be reached by input results, but all the more by missing or unclear results. However, the state model reacts on this state also. Usually this state is reached during cluster startup, when no persistent state was set before stopping GSCC. “Operator” is a persistent state, which would be remembered during startup. Other states will not be accepted anymore. This will be covered in more detail in a later section. An “Unknown” situation is resolved by the current expert domains with a “Join” to verify the resource status of the member. Other situations to receive an “Unknown” are old status information from a partner or peer member. In rare cases wrong input method results can cause the cluster to be unable to define the next state. In this situation also the “Unknown” state is used to resolve the problem. If this occurs regularly it is necessary to check the gscc.log as this might be caused by insufficient timeout values or even a bug in the expert domain.
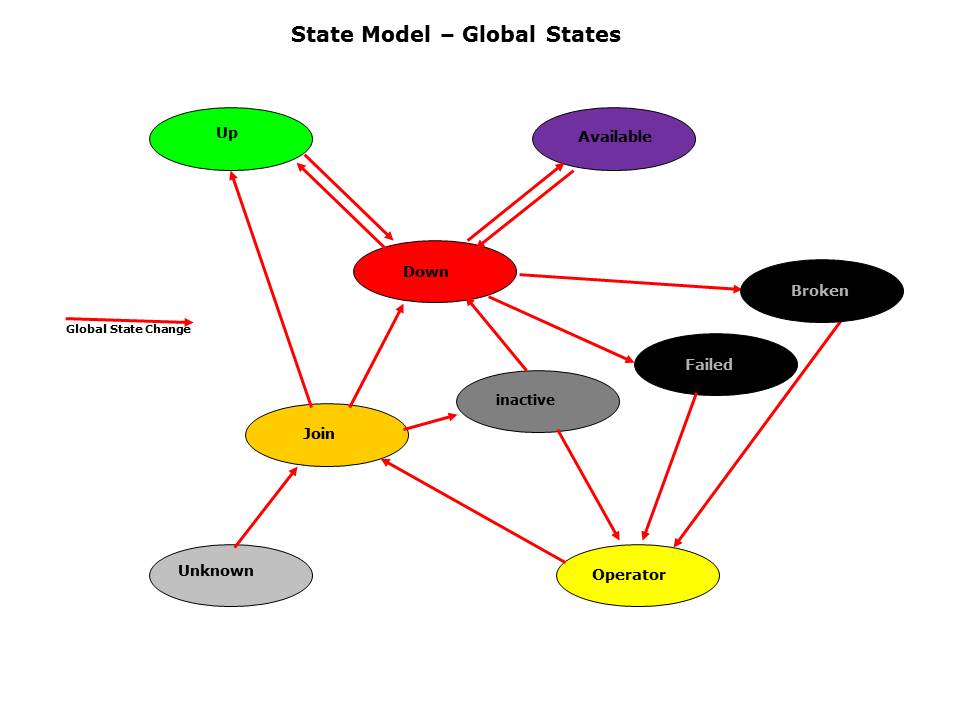
Base State Model GSCC
The figure the main global state switches are shown. During startup of GSCC all member will enter the state model through “Unknown” or if a persistent state like “Operator” was detected through “Operator”. In this case GSCC will stay in “Operator” until the administrator uses the “Join” command to activate the cluster again. In both cases the next state will be “Join”, where GSCC checks the currently activated resources in order to decide, what to do next. If ISP is running controlled by a certain member, GSCC will set the member state directly to “Up” and starts cycling through the local “Up” states. If no resources are activated at all, the “inactive” state is reached. After reboot of both cluster systems no resource are active. In that case all member in the member team will switch to “inactive”. Though “inactive” is a stable state, there is an reaction on the so called “inactiveConflict”, which is resolved by the cluster then and activates one of the partner members to add the resources.
Expert Domains
The entity to configure the GSCC behavior is the expert domain. A expert domain consists of defined states and rules. An expert domain can be changed easily, when the requirements to ISP for that behavior is met.
There are four main types of expert domains to manage ISP instances. The types of expert domain differ mainly in the way the failover occurs. As explained before GSCC supports HADR configurations and different volume manager configurations. This means GSCC can use database functions to take over the ISP instances and/or volume manager functions to make an ISP instance available again. The decision which is the better alternative is really depending on the environment and the requirements.
GSCC offers therefore all possible combinations, which is possible due to the expert domain architecture. The four main alternatives are shown in the following chart. The upper configurations are using a member team with 4 members and provide a combination of shared disk failover based on volume management and HADR. Prerequisite here is the possible to activate the resources of the databases independently on both hosts. Manually both takeover ways can be performed, but the main difference in the two expert domains is the primary failover decision in an uncontrolled situation. An uncontrolled situation is detected, when a complete host fails or is unreachable. Expert domain 1 would in such a situation first execute the HADR failover. This is useful when a shared disk failover is considered more likely to fail as a result of reservation or limitation on the shared disk subsystem. Expert Domain 2 in contrast would primarily failover the primary database by using the shared disk resources. However, in a second step even here the standby can be used to activate ISP.
The two lower expert domains are limited to a single takeover alternative. The HADR, IP only alternative can only failover with HADR methods. It is typically used in a non-SAN setup where even the ISP resources are on local disks. The 4th alternative expert domain is only using shared disks to failover to the other hosts. HADR is not configured at all. This is a version where the complexity is not needed and in case of major issues a restore is quickly performed as it is small in size.
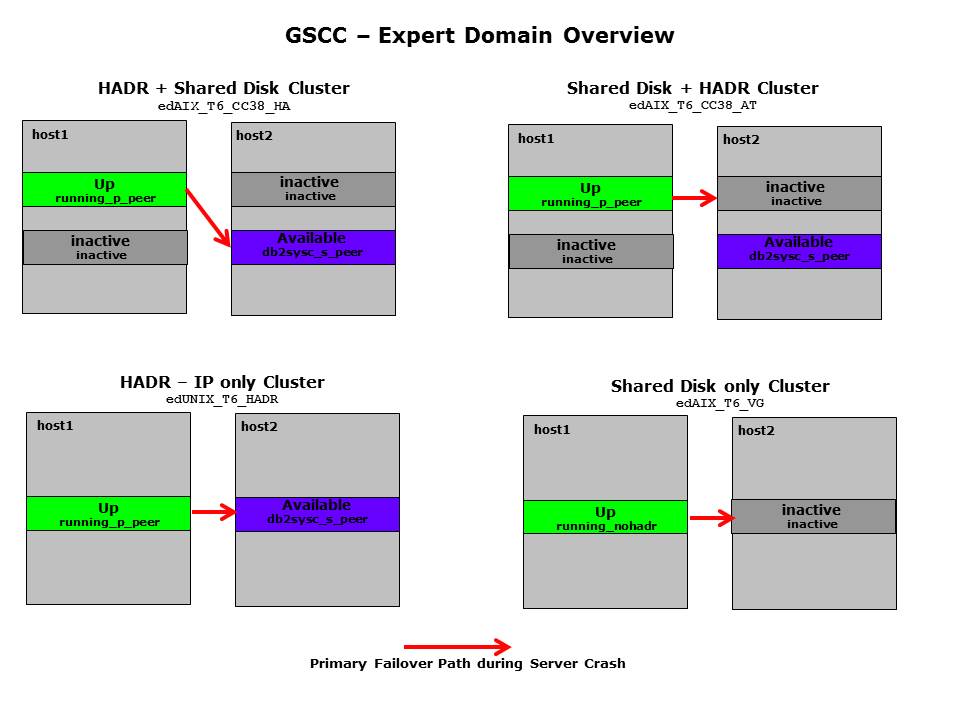
Expert Domain Overview
The GSCC cluster supports different failover scenarios. These are the two main mechanisms that are used. These can be configured by itself or in a combination with the other.
- Shared disk failover
Volume Manager Failover like LVM
Shared Filesystem like GPFS
- Standby database failover
ISP Classic Sync
DB2 HADR (High Availability Disaster Recovery) log shipping
As GSCC is based on a state model the behavior can be changed relatively easy. The needed rules are defined in rule sets. These rule sets then are combined in a so called “Expert Domain”. There are tested and verified “Expert Domains” for the different failover scenarios. It is recommended to use these predefined configurations when using GSCC. However, it is possible to adjust certain detailed steps according to different requirements.
ISP Resource Layout
For the administration of GSCC it is important to understand the different resources which are controlled for an ISP instance. There are 5 areas of resources:
- ISP Home Disk Resources
Home Filesystem with ISP option file etc.
DB2 Instance Directory (ISP6/7 - optional in Home Resource) etc.
ISP Database Volumes / file systems
ISP Log Volumes (Active Log, Archive Log, Mirror Log, Failover Log)
- ISP DB2 HADR Resources
HADR “Primary” IP-Address
HADR “Secondary” IP-Address
DB2 Database HADR
- ISP Storage Pool Resources
Filesystems and Raw Devices for ISP Disk Storage Pools
- ISP Server Process
Starting and Stopping ISP Instances
- IP Address ISP Instance
Moving the IP Address of the ISP instance to another host (s. Service IP)
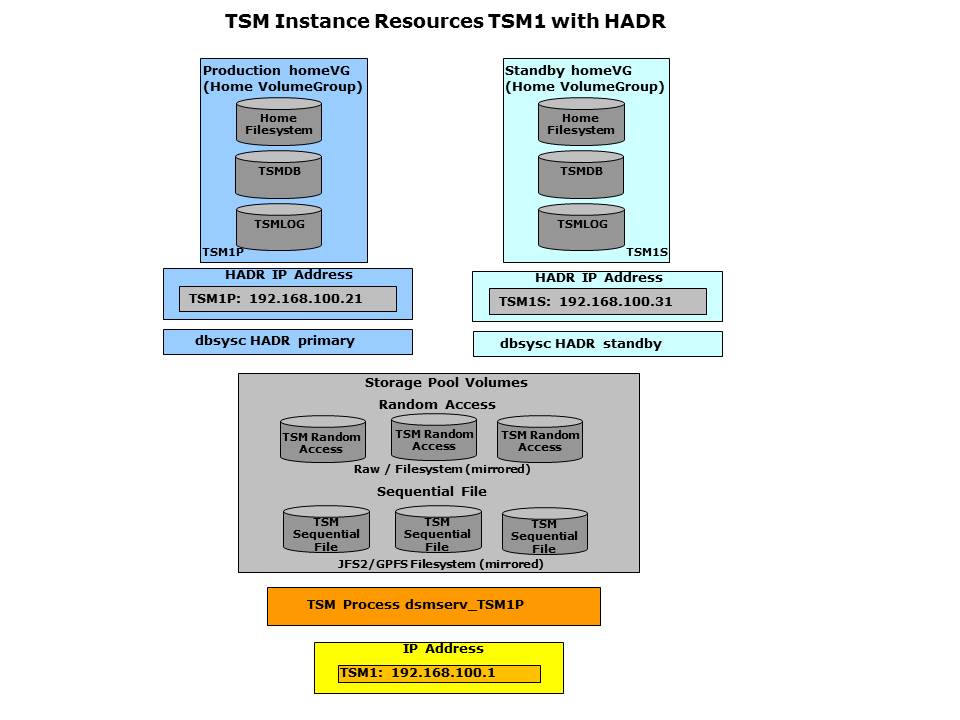
ISP Instance Resources – HADR
ISP Home Disk Resources
Each ISP instance in a cluster setup needs its own environment with which it is started. This means the ISP instance requires separate volumes for the database, logs and the configuration (dsmserv.opt). In order to take over the original primary database to another system these volumes must be available on the SAN. If a takeover is HADR based only these resources can also be local disks. Within GSCC this resource is referred as Home Disk or simply HomeVG (Home Volume Group).
In the shared disk setup this must be at least a separate LUN in a dedicated Volume Group or Disk Group depending on what volume manager is used. The configuration files are in a separate filesystem (Home Filesystem or Config Filesystem) as well as database and logs. GSCC also supports an independent standby database for each productive ISP instance. The standby database for HADR or classic sync requires a separate HomeVG.
ISP DB2 HADR Resources
In a HADR configuration further components besides the disk resources are required in case the primary and the standby are supposed to be movable between the systems independently. The primary and standby database must be able to communicate with each other. In HADR are IP addresses and ports defined. In a flexible cluster setup IP aliases are needed for each side to ensure communication independent from the system the DB2 database is activated. - HADR “Primary” IP-Adresse - HADR “Secondary” IP-Adresse - DB2 Database HADR
ISP Storage Pool Disk Resources
In a GSCC setup with a secondary database the disks for the storage pool have to be placed on a separate disk, which can be activated independently from the home disk resources. The storage pool disk resource can that way be activated for the primary or the standby database in case of a failover. The storage pool disk resources can be shared SAN disks or other shared disks like GPFS or NFS.
ISP Server Process
The ISP server process is of course the most important resource in a GSCC cluster. It is possible to run several instances on the same system. The processes are started in independent environments represented by the home disk resources described before. In the process list the instance name can be found in the process name as GSCC uses a symbolic link including the name to start the process.
root@aix1 [/root]
%ps -ef|grep dsmserv
root 290976 360704 0 21:19:57 pts/0 0:00 grep dsmserv
root 7667872 1 0 Sep 14 - 7:03 ./dsmserv_ISP53P quiet
ISP11p 9437296 1 0 Nov 18 - 0:28 dsmserv_ISP11P -i /ISP/ISP11P/home –quiet
Service IP Address
Each ISP instance has at least one IP address assigned, which is used for Backup/Archive clients, other ISP server or administrative clients can connect to it. This IP address is a virtual address which can be moved between the systems just as the ISP instance. The address usually also has a DNS alias with the ISP instance name. In GSCC these addresses are called service IP addresses.
The service IP addresses are defined as IP aliasses on physical interfaces. It is recommended that these physical interfaces are redundant. This might be a channel or a backup adapter configuration. This is the tabular view of IP addresses in a cluster:
aix1
DNS Alias IP-Adresse Interface Funktion
aix1.net.de 192.168.100.101 en4 Management
aix2
DNS Alias IP-Adresse Interface Funktion
aix2.net.de 192.168.100.102 en4 Management
ISP Instanzen
DNS Alias IP-Adresse Interface Funktion
libm.net.de 192.168.100.3 en4 ISP LIBM IP Alias
ISP1.net.de 192.168.100.1 en4 ISP Instanz 1 IP Alias
ISP2.net.de 192.168.100.2 en4 ISP Instanz 2 IP Alias
This is an AIX example of IP addresses:
root@aix1 [/root]
%ifconfig –a
en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN>
inet 192.168.100.101 netmask 0xffffff00 broadcast 192.168.100.255
inet 192.168.100.3 netmask 0xffffff00 broadcast 192.168.100.255
inet 192.168.100.1 netmask 0xffffff00 broadcast 192.168.100.255
tcp_sendspace 131072 tcp_recvspace 65536
en5: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN>
inet 172.16.100.101 netmask 0xffffff00 broadcast 172.16.100.255
tcp_sendspace 131072 tcp_recvspace 65536
lo0: flags=e08084b<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT>
inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255
inet6 ::1/0
tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1
root@aix2 [/root]
%ifconfig –a
en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN>
inet 192.168.100.102 netmask 0xffffff00 broadcast 192.168.100.255
inet 192.168.100.2 netmask 0xffffff00 broadcast 192.168.100.255
tcp_sendspace 131072 tcp_recvspace 65536
en5: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN>
inet 10.96.34.53 netmask 0xffffff00 broadcast 10.96.34.255
tcp_sendspace 131072 tcp_recvspace 65536
lo0: flags=e08084b<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,
ROUPRT,64BIT>
inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255
inet6 ::1/0
tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1