Example Scenarios
SAN Configurations
This chapter covers common Operator tasks in a shared disk setup and it provides step by step examples for the different situations. The different activities are performed with GSCCAD, but all of them could also be performed with the command line interface “gsccadm”. The following scenarios are covered. Be aware that some scenarios are valid only for certain Expert Domain configurations.
SAN - Starting Point
The first figure shows a typical starting point for a GSCC cluster setup. It is the base for the most scenarios described here. The examples always look only at a single ISP instance with 4 members in the member team. Some Expert Domains like IP cluster or Shared Disk only cluster work with just two members in a cluster, but this is mentioned accordingly.
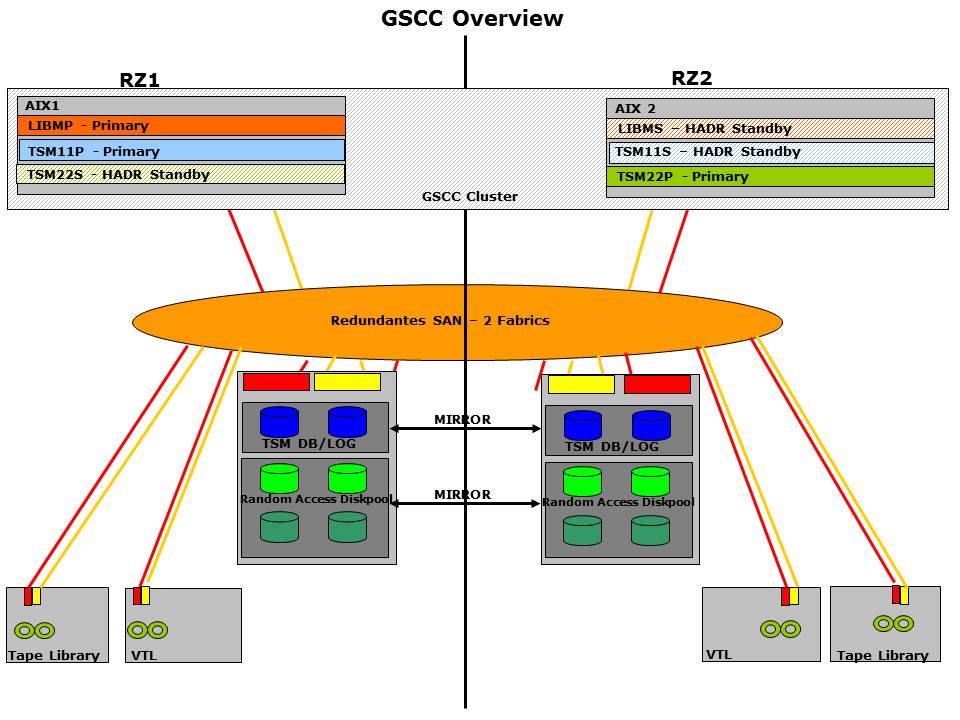
GSCC Example: Starting Point
In these examples we are looking at a single ISP instance, TSM11, with in most cases a 4 member configuration. This means shared disk resources and HADR are configured for TSM11.
The next chart is the member and resource overview cart which is used throughout the GSCC scenarios to visualize the state changes in certain situations. Inactive resources are covered to see where they could potentially be activated. In this setup it is important to understand that the primary and standby database has its own group of independent resources (HomeVG), while other resources are shared between them like storage pool and IP addresses. The standby (Available) resources are shown in a purple color while the primary resources (Up) are shown in green. Shared resources are light blue.
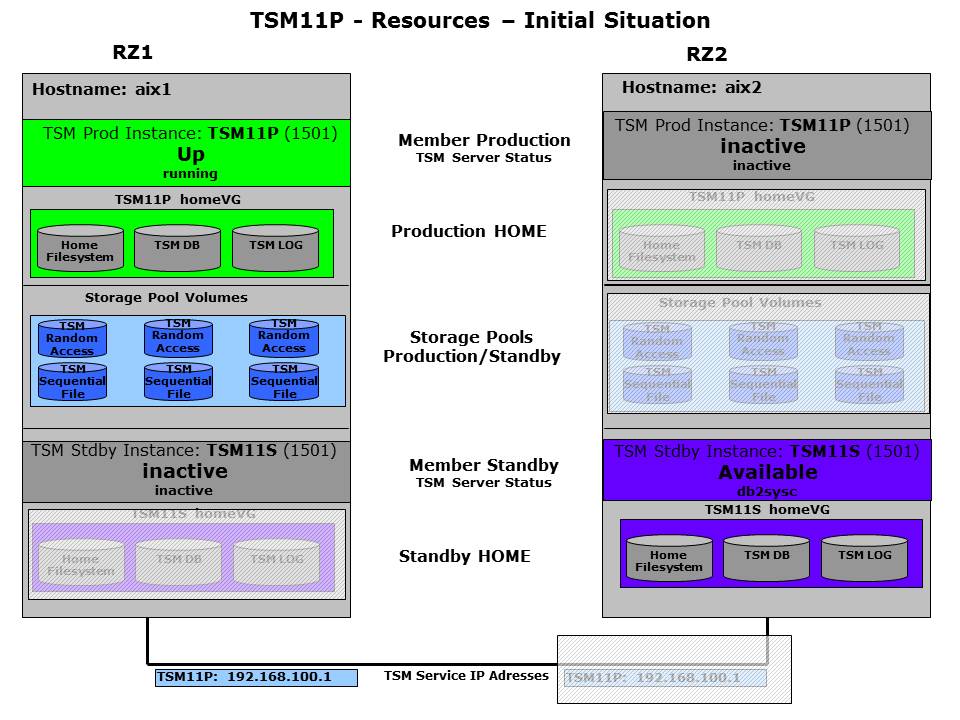
TSM11 Resources – Starting Point
GSCCAD
In case the cluster is in a normal state, the GUI “Sites View”-tab would look like this:
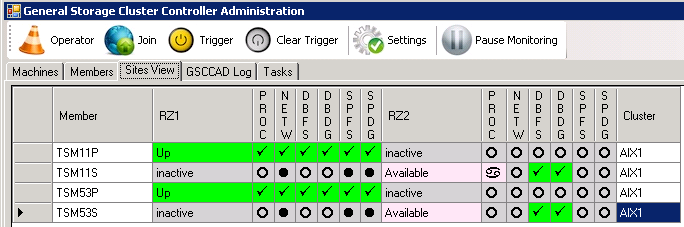
Initial Situation: OK
gsccadm
In “gsccadm” the same status would be checked as follows:
gscc aix1>q status
121119181345 TSM53P Up
121119181400 TSM53S inactive
121119181245 TSM11P Up
121119181345 TSM11S inactive
You have to be aware that in the CLI the status information is only returned from the local cluster side. Command routing (Hostname:command) can be used to also check the opposite cluster side:
gscc aix1>aix2:q status
aix2 returns:
121119181437 TSM53P inactive
121119181522 TSM53S Available
121119181438 TSM11P inactive
121119181438 TSM11S Available
SAN - ISP Instance Maintenance
One possible ISP administration task is to restart an ISP server instance. When an ISP server is stopped by the administrator and GSCC is active, GSCC would just restart the instance. This might in some cases be enough. In other situations ISP must be stopped, some changes on the system need to be performed and ISP is started again afterwards. This kind of maintenance task requires it to give the control to the administrator or operator and not GSCC automatics. GSCC is not stopped in this case, but the state of the different members is changed to Operator, in which GSCC is not reacting on activities on the ISP resources. In Operator Mode (all member in the member team in state Operator) GSCC also provides wrapper commands to control ISP resources. This section will go through the steps to perform a maintenance task in the Operator Mode.
The following member state chart shows the target status for the members of TSM11’s member team. All members have to be in the Operator state and even if only one member would be in Operator all other member would follow automatically. Even if the state is Operator the actual resources are not changed at all.
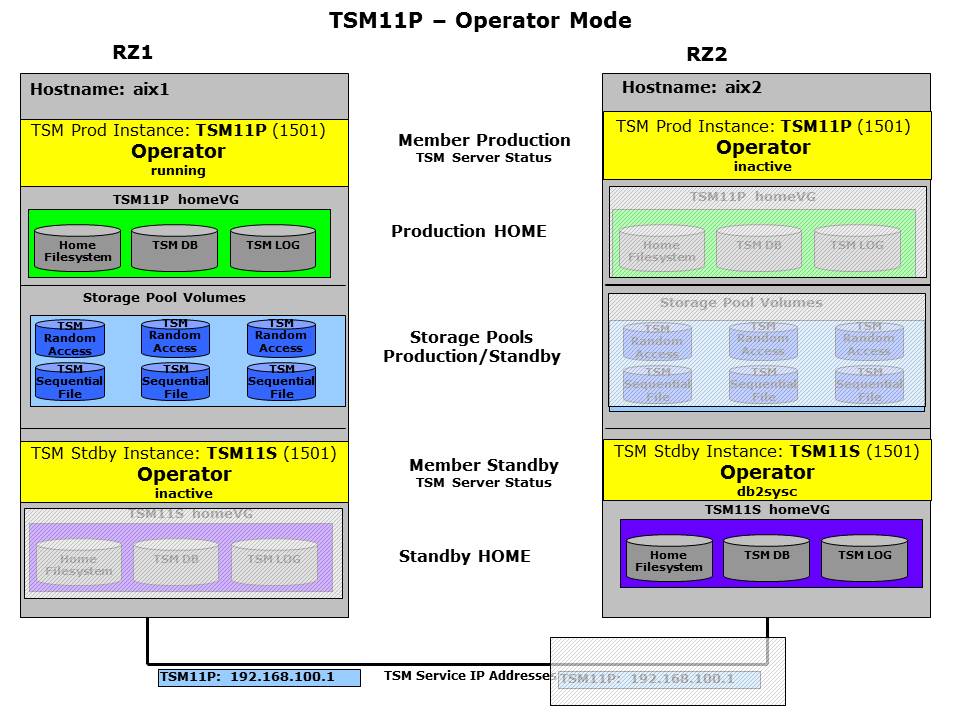
Operator Status – TSM11 Member Team
Enable Operator Mode
Operator Mode in GSCC is not a simple switch which is executed by pressing the Operator button. This button is rather a request for that state. This is necessary to allow GSCC to finish up the recent tasks or checks. Usually the Operator state is requested on all members of the member team at the same time. However, GSCC would automatically ensure that all other member follow into Operator state anyway.
To switch into Operator state for ISP instance TSM11 we logon to GSCCAD. In the “Sites View” tab you can chose the members. You can choose more than one member at a time by using shift-mouse or ctrl-mouse on the state field. Be aware that with shift-mouse also the fields between the member states are selected, but this will still work as all other fields are ignored. After having selected the correct members press the “Operator” button at the top.
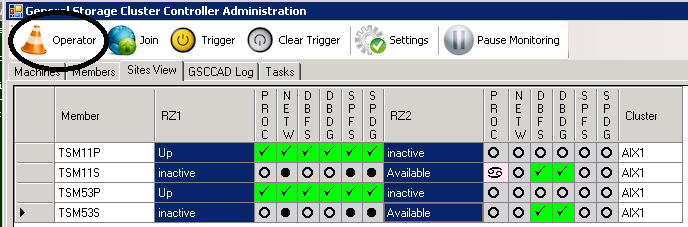
Activate Operator Mode
A confirmation window will allow to double check, which members you want to switch to Operator state.
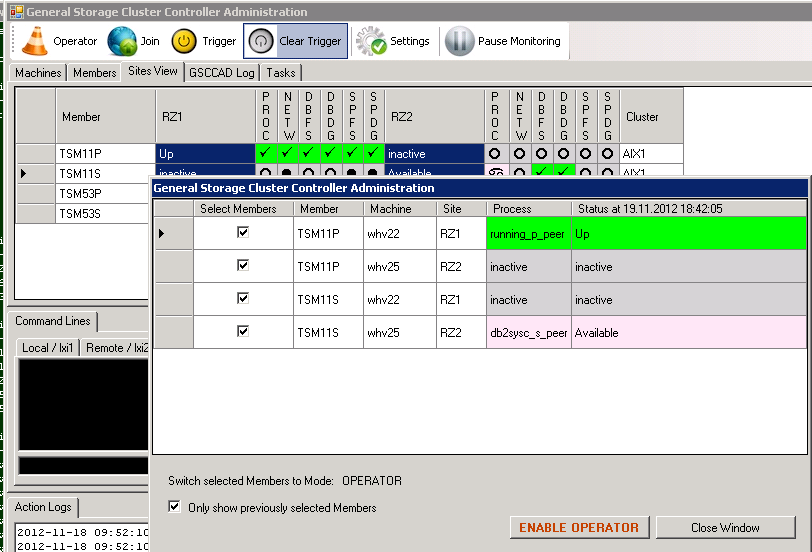
Confirmation Request
As we want to change the state for all members for TSM11 our selection was correct and we confirm the request for Operator by clicking on “Enable Operator”.
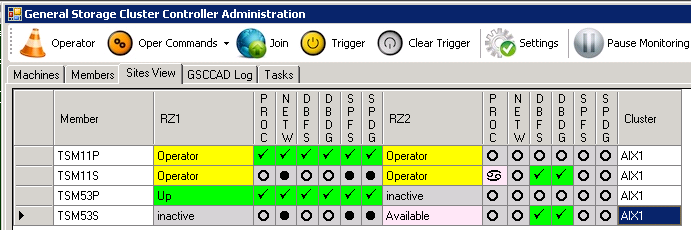
Operator Status
After some time all member states will change into Operator. You are now in Operator Mode with TSM11. GSCC would not react on any action for that instance. Be aware that TSM53 the other ISP instance in the same cluster is not in Operator Mode, so GSCC would still react here. If we would need to perform a system activity like reboot etc. we would need to switch all member teams in the cluster to Operator. The automatic Operator switch is only performed within a member team, not within a cluster.
5.2.2 Maintenance If the TSM11 member team is in Operator Mode, the ISP instance can be stopped and started without intervention by GSCC. In Operator Mode the administrator has the control over the ISP server. If there is a system maintenance or GSCC maintenance all GSCC member have to be in the Operator Mode. While in Operator Mode you could use the common way to stop and start ISP. However, it is recommended to use the GSCC Operator Commands instead as they take care about all other resources like IP addresses, HADR etc. as well. In this example the GSCC Operator commands are used to stop and start ISP. In GSCCAD “Sites View” you can see the Operator status, but the resources of TSM11 are still online.
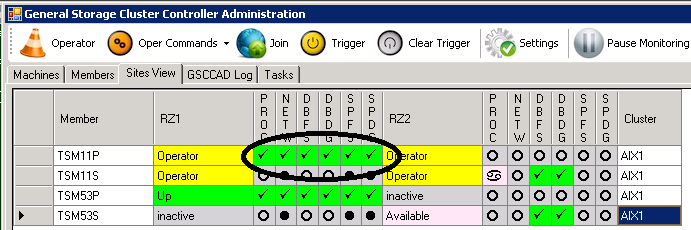
Resources ISP1P online
You first select the member where ISP is currently active. Then choose the “stoptsm” button in the “Oper Commands” menu to request the stopping of TSM11.
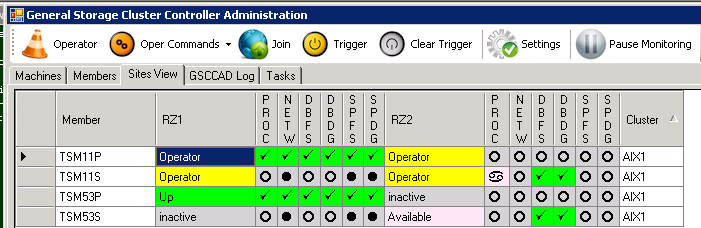
TSM11P in RZ1 selected
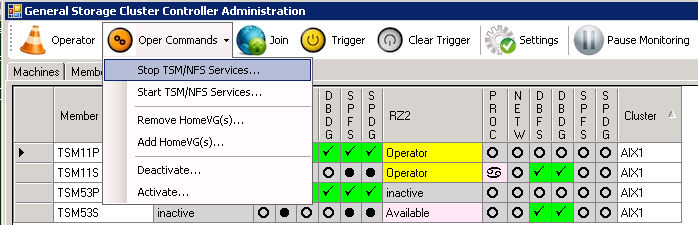
“Stoptsm” selected
GSCCAD should open a window only showing the member of the active ISP instance. Verify that the correct member on the right system is chosen. You can see the ISP process status to double check. The actual command needs to be confirmed here again.
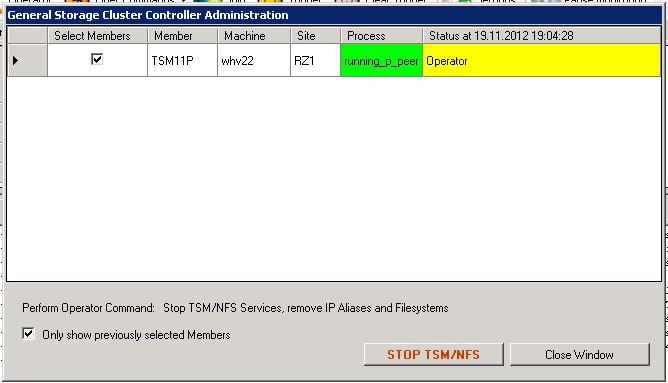
Operator: stoptsm
While on the “Sites View”-tab you can follow the progress of stopping ISP and even the standby process. At the same time you can follow the different steps in more detail in the “Action Logs” view.
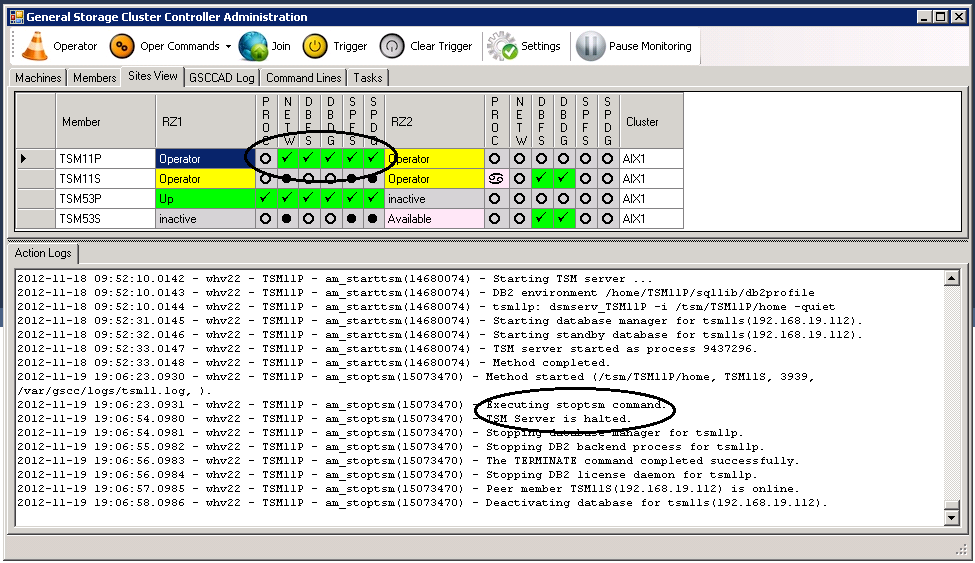
ISP Server is stopping – Step 1
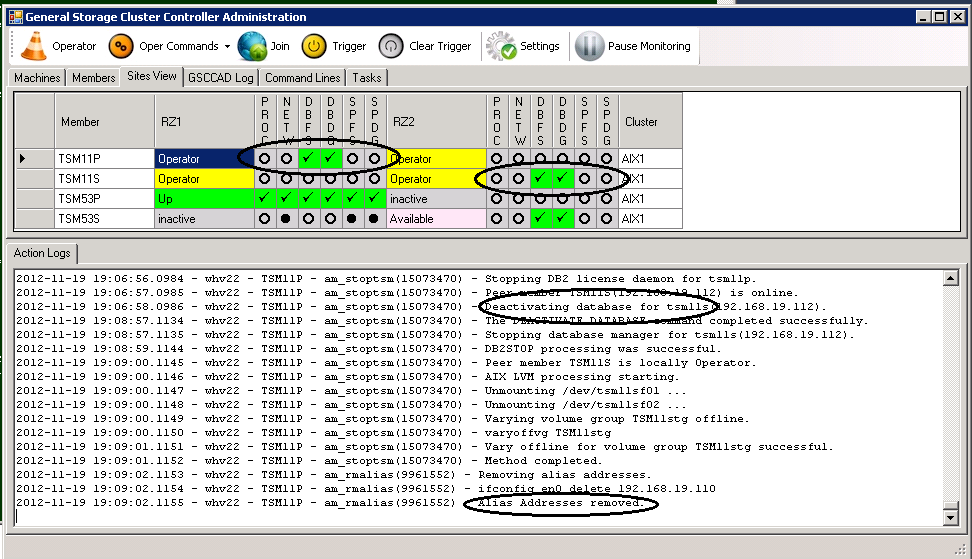
ISP Server is stopping – Step 2
The Operator tasks like the stopping of ISP can be checked in the “Tasks” tab.:

Task Overview
Be aware, that in this example we only stop the ISP instance. The HomeVG resource was not deactivated. In order to switch the instance to the other host it would another step be required, which will be covered later. Should the ISP instance be started again, the same procedure needs to be followed. There is also a “Start ISP” command. These are the steps for starting the ISP server with the Operator command.
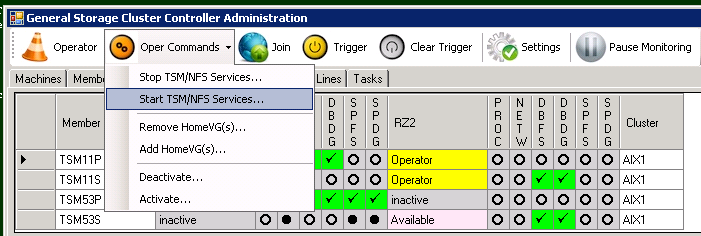
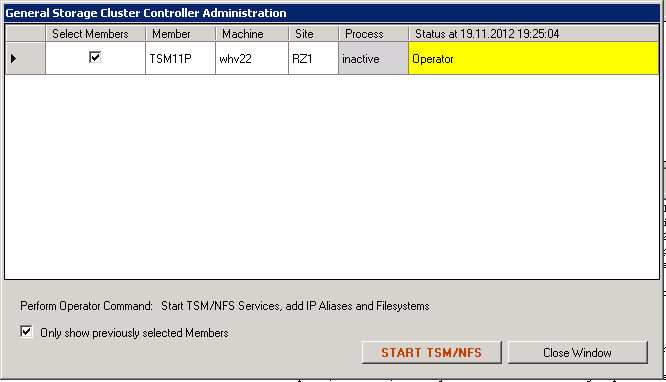
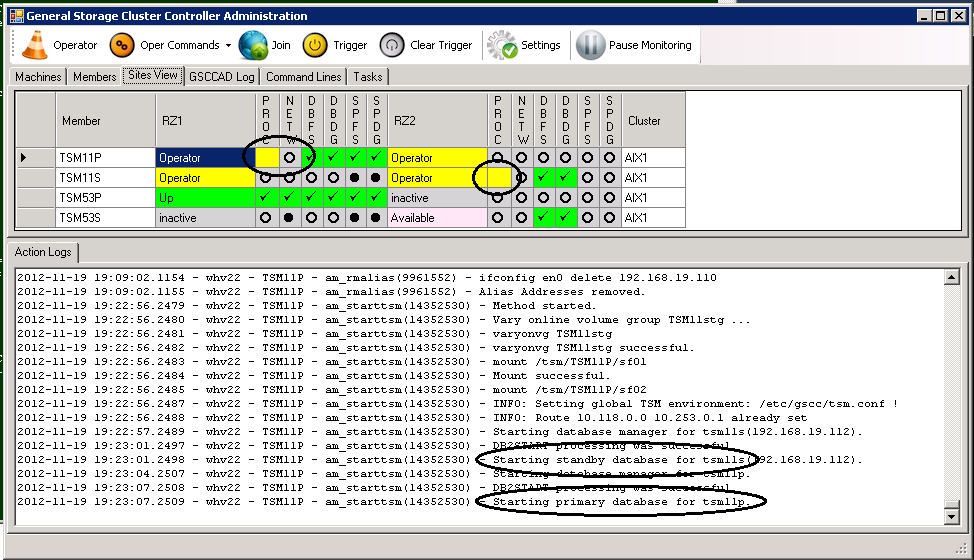
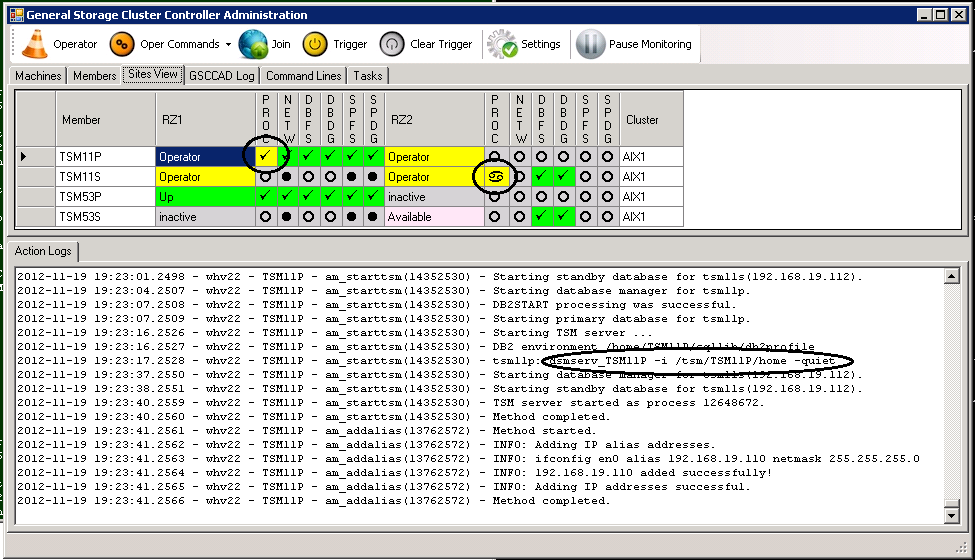
Steps for “starttsm”
Again the details can be watched in the “Action Logs”-tab. The process status can be also seen in the respective column. In this case the process status icon is first yellow. This means that HADR is still catching up and not yet in sync (in peer as it is called in HADR). GSCC will stay in Operator Mode after these actions. The Operator Mode can be left by using the “join” command for all members in the member team.
Exit Operator Mode
As soon as the maintenance jobs were performed, GSCC automatics can be activated again. This step is called as “Join” in GSCC. Accordingly there is a “Join” command to do so. All members in the member team need to receive the “Join” command. As long as one member is still in Operator the actual join will not be performed. This is required to ensure a save activation. After selecting all members and pressing the “Join” button, all members will switch into the state also called “Join”. During this state GSCC waits for other members to also be in this state. The next step then is “Joining”, where GSCC checks the current status of the ISP resources and would switch to the according global state.
In our example the GSCCAD steps are the following. We first select in the “Sites View”-tab all four members (ctrl-mouse) and then execute the “Join”-command. We need to confirm that we really want to send this command to all 4 members we previously selected.
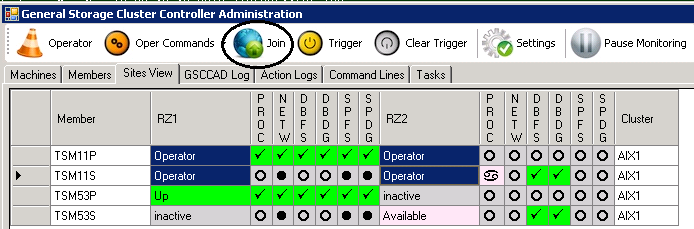
Operator Command “Join”
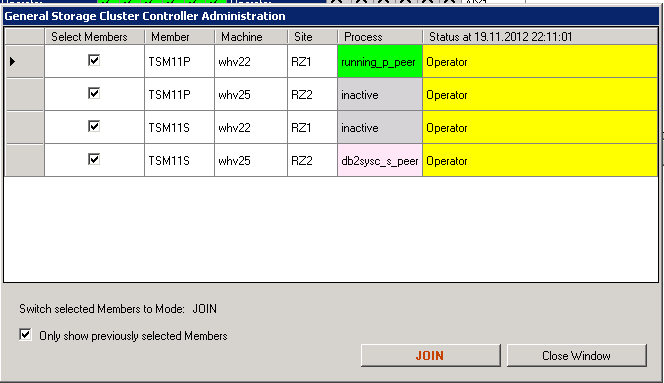
Operator Command “Join” needs to be confirmed
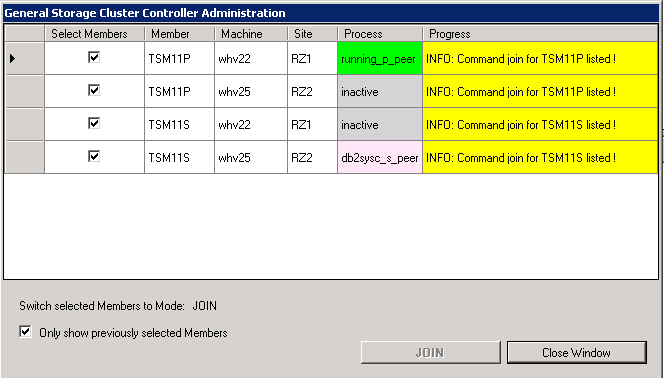
Join Commands are listed
In the status display you can see all members are switching into the state “Join”.
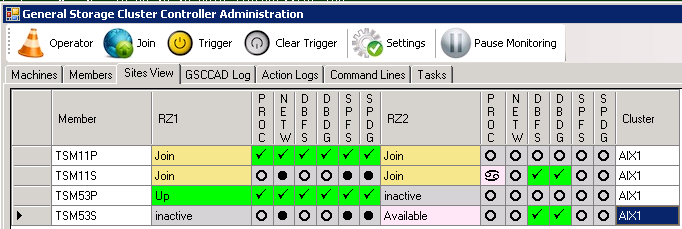
GSCC starts “Join”
Now GSCC verifies the situation on the hosts. As we started ISP again after we stopped it, GSCC will detect the running instance. Therefore after the “Join” status that member (TSM11P in RZ1) will go to the “Up” state immediately and start to cycle through the different “Up” local states to ensure that all resources are available. The partner member (TSM11P in RZ2) will switch into “inactive” as the HomeVG resource is on the other host. The standby HomeVG is activated in RZ2, therefore the “Down” state is displayed. As soon as HADR availability is detected the “Available” state will reached.
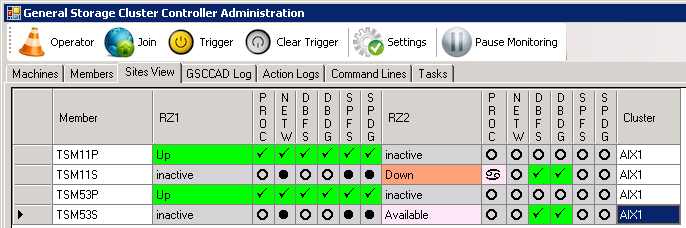
Temporary status while returning into normal status again
Then the cluster join is completed and the members are in the original states.
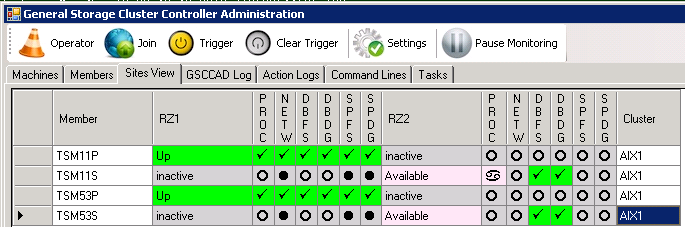
Normal Status
SAN - Planned ISP Takeover
If the ISP instance should not be started on the same host again, but on the remote host, a planned takeover can be performed. Depending on the configured expert domain this can look different. This takeover scenario describes a shared disk configuration. With a pure IP based cluster this is not possible and the process will be documented later in this chapter. To all other expert domain which have shared disk resources this description apply. So even in the case where in an uncontrolled situation the HADR failover is the first choice, it is still recommended to use the shared disk takeover in a controlled maintenance situation rather than the HADR takeover. During the planned takeover all resources have to be moved to the other side including ISP primary database, logs, ISP home filesystem, storage pool volumes and IP addresses. The starting point is again the joined cluster for ISP instance TSM11 with the typical states.
Resources – Starting Point
The goal is to move the ISP instance, currently controlled by member TSM11P in RZ1, to the other host, where the partner member TSM11P is inactive. Therefore all resources need to be moved accordingly.
The next figure shows the planned status after the move. There are no resources at all for TSM11 on the first host anymore. HADR would still be in peer, but the logs would be shipped locally to the standby. This is possible as also the IP resource for HADR will be moved together with the HomeVG.
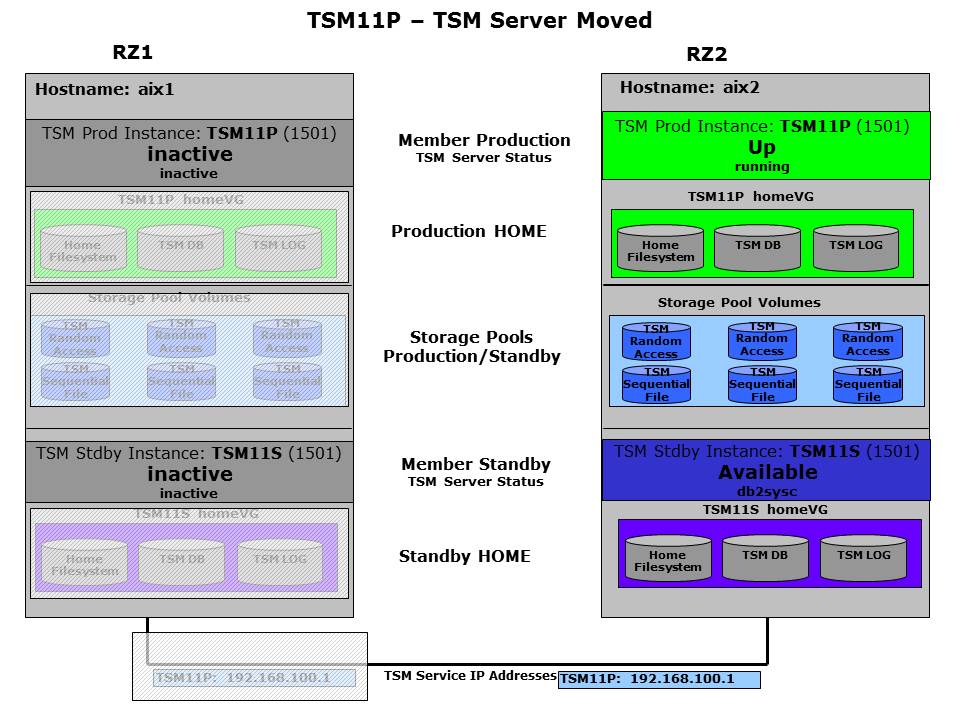
ISP Resources have been moved
Operator Mode
As you have seen in the example before the first step is always to switch into Operator Mode. In order to document the required steps that procedure is also included here.
The Operator Mode will be requested for the members “TSM11P” and “TSM11S” on both sides:
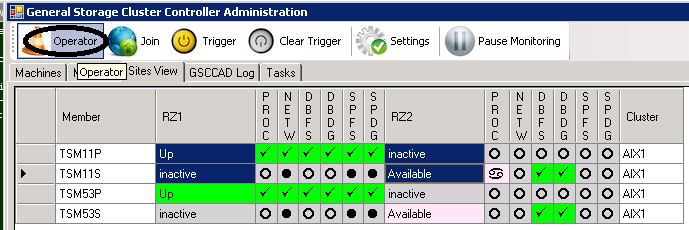
Request Operator Mode
We should see this picture again:
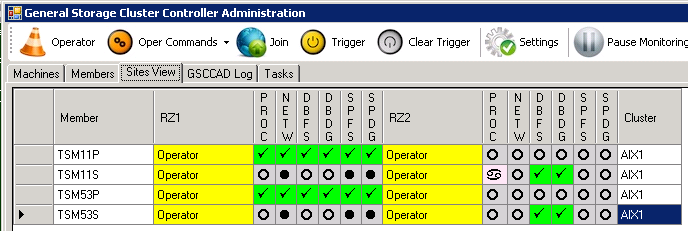
Operator Mode TSM11
Deactivating ISP
As soon as the member team for ISP instance TSM11 is in Operator Mode, the ISP instance can be stopped and the resources can be deactivated. In GSCC there are two steps necessary.
1. Stop ISP Instance (stopping DB2, HADR standby, remove storage pool disks and service IP addresses) gsccadm-Command: operator stoptsm TSM11P
2. Deactivate ISP HomeVG (remove HADR IP Aliasses) gsccadm-Command: operator rmhomevg TSM11P In contrast to the example before, not only the first step needs to be performed, but also the HomeVG must be removed. In certain situation it might be useful to do this in 2 steps, but for convenience reasons the two steps (stoptsm and rmhomevg) can be performed in a single command: “operator deactivatetsm TSM11P” In this example we actually use this command. So we need to select the member, which currently controls the ISP instance and choose “deactivatetsm”.
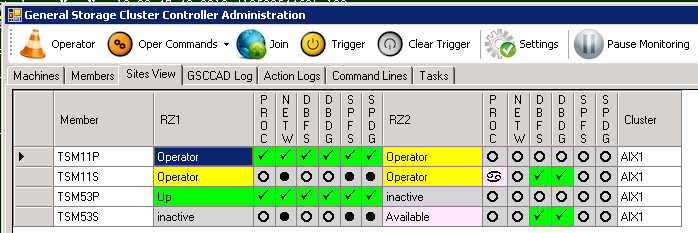
ISP Server Member TSM11P selected
“Deactivate” selected
GSCCAD requests again to confirm the planned action. It is important to verify that the correct member was selected. Though GSCCAD does some checking to avoid errors, in certain cases it would just perform the requested action. In this example we see that we selected the member which actually controls the ISP instance (running_p_peer).
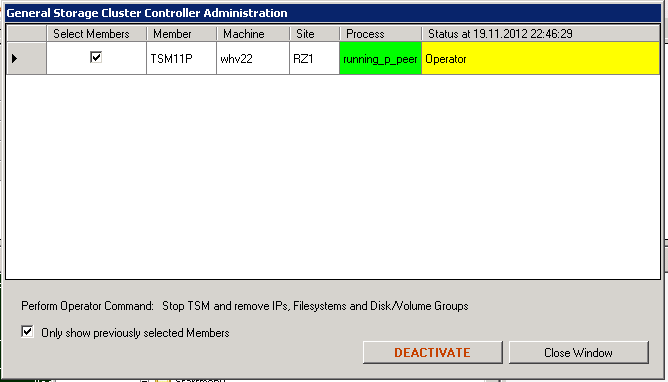
Execute “Deactivate” Command
The “deactivatetsm”-command will finally then perform the two steps. But it would check that the first step was successful before starting the next one. So GSCC begins to stop the ISP instance.
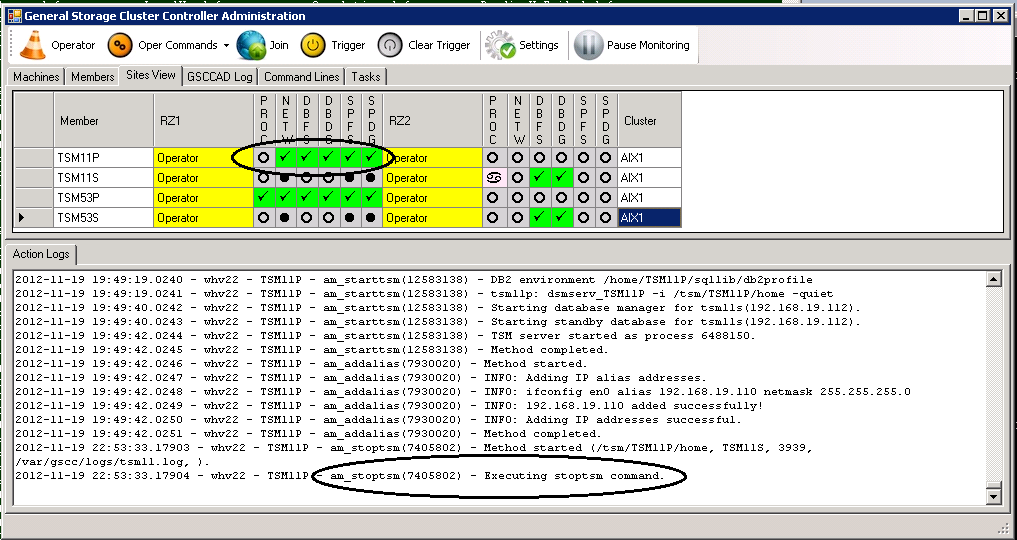
First Step of “deactivatetsm”: stoptsm
Then GSCC continues to remove the HomeVG, so as seen in the next chart all resources for TSM11P in RZ1 are offline.
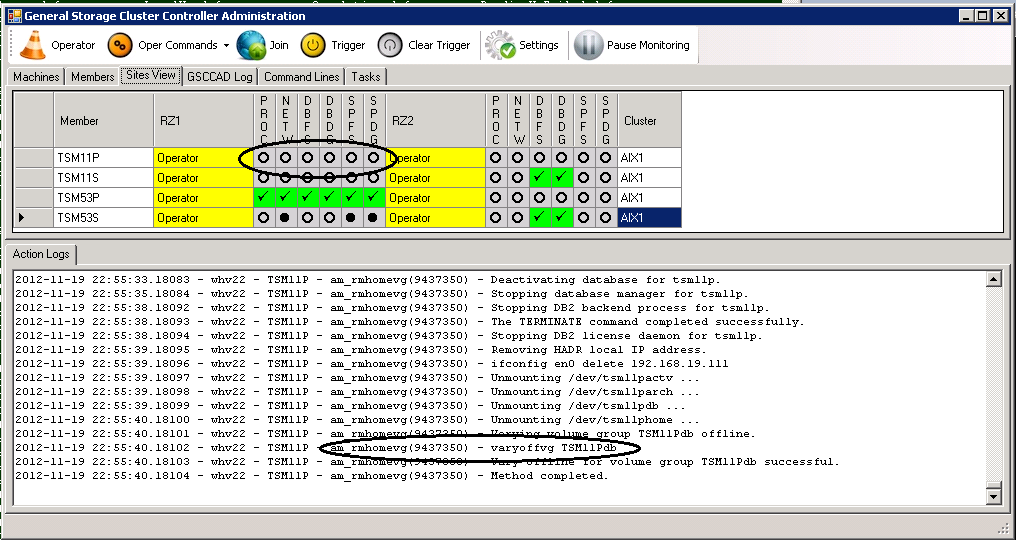
Second Step of “deactivatetsm”: rmhomevg
Activating ISP on Target System
The ISP instance is now completely deactivated on the original system. Even the HomeVG disk resources are offline. While still in Operator Mode the ISP instance can now be activated on the remote system. Again this would require two independent GSCC steps: 1. Activate ISP HomeVG (add HADR IP address) 2. Command: operator addhomevg TSM11P 3. Start ISP Server (start DB2 and HADR standby, add storage pool disks and service IP addresses) Command: operator starttsm TSM11P
In certain situation only the HomeVG should be activated in the first step, before already starting ISP (for example ISP update). Then you would only use the “addhomevg” command. Since we plan to immediately starttsm, the best way is to use the combined command “activatetsm”/”activate” now. GSCC is still in Operator Mode for TSM11. So the command can be executed by selecting the member which should control the ISP instance and click “activate” then.
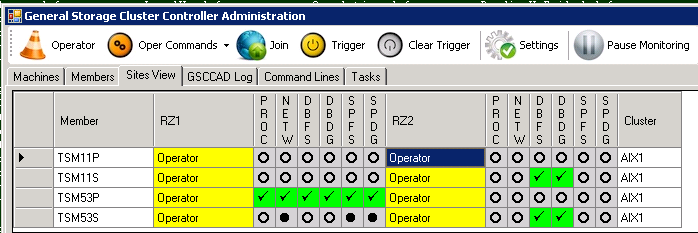
Member selected
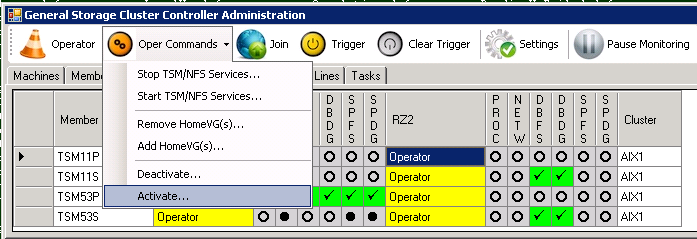
Operator Command “activate”
The member and the command can be verified again, before actual starting it.
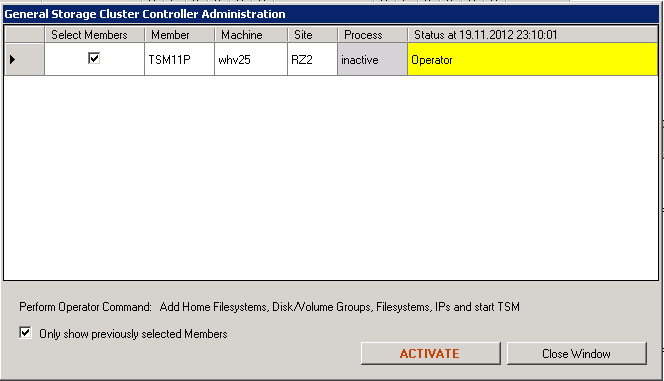
“Activate” Command Confirmation
The first step for the “activate”-command is to add the HomeVG (see columns DBFS/DBVG and the detailed action log):
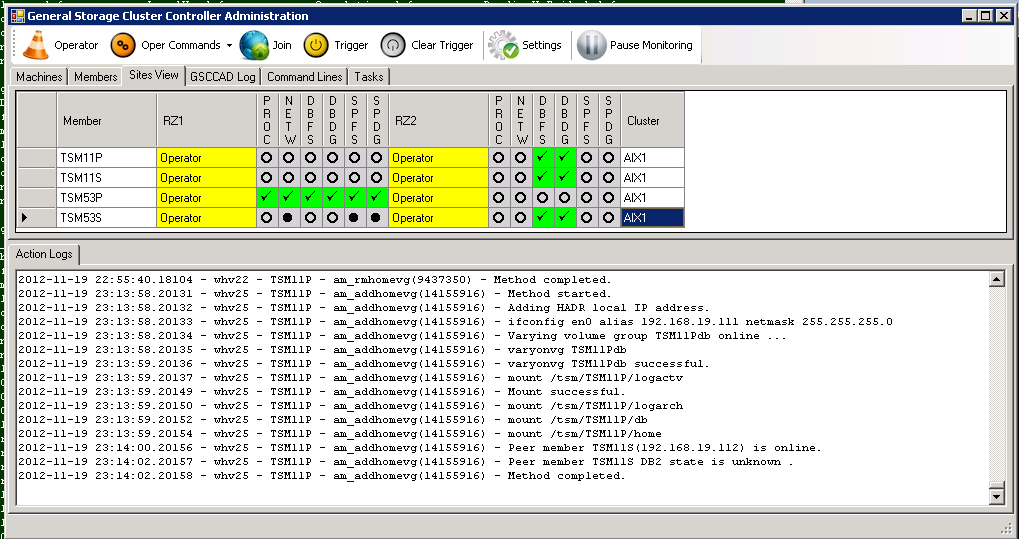
“activate” Command – Step 1: addhomevg
When this was successful, the second step is initiated: starttsm. First the storage pool VG is added and then primary and standby DB2 database are started.
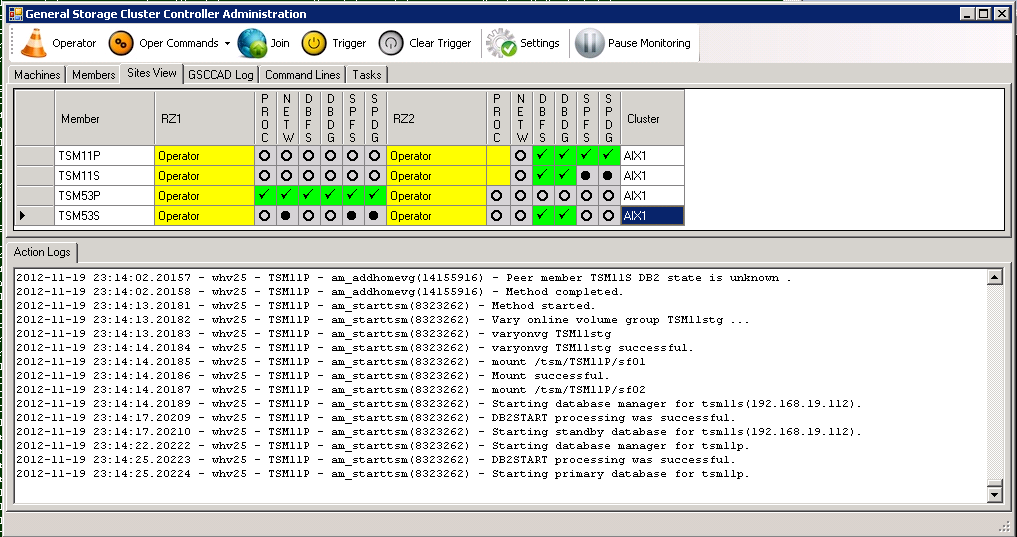
“activate” Command – Step 2: starttsm
Now ISP is started and finally the IP alias is added. HADR primary and standby take their role and start to sync.
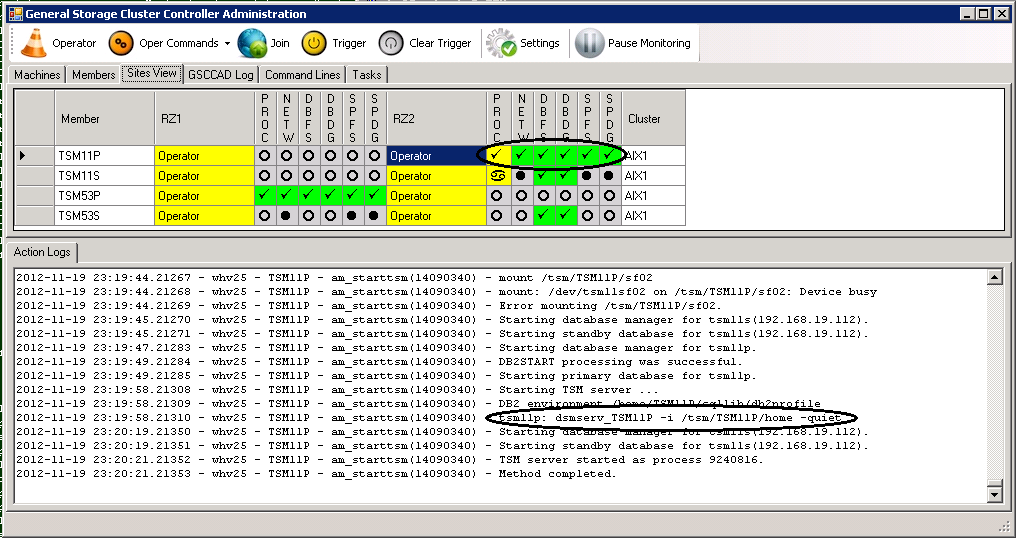
ISP Server is starting
When the process column is showing the check sign on green background everything went well. In case this would stay yellow, the sync was probably not successful.
Now the cluster can be activated again by performing the “Join”.
Activate Cluster: Join
Is the ISP instance running on the correct side and this is not a temporary action (like a system maintenance job), it is recommended to join the cluster. So again all members for TSM11 must be selected and the “Join”-command has to be run.
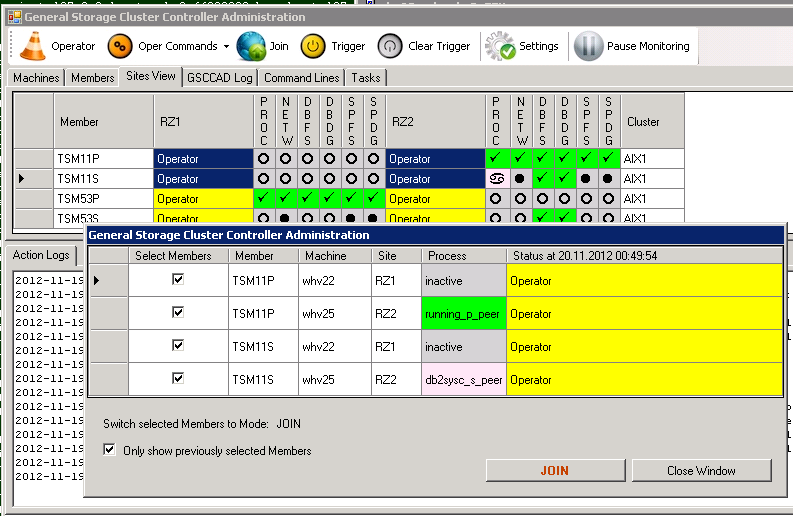
“Join”
All 4 members should switch to the state “Join” then:
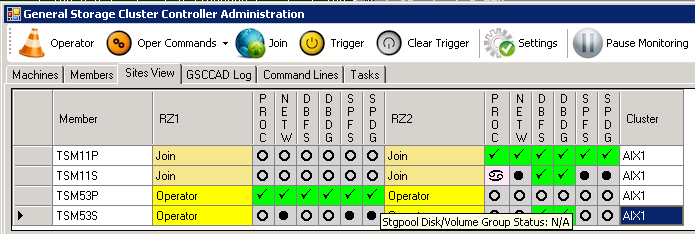
“Join” States
GSCC detects, that the ISP instance is running on the second hosts and will go to the “Up”-state directly for that member. As the standby HomeVG wasn’t touched, the “Available”-state is set for the other member on the same system (TSM11S).
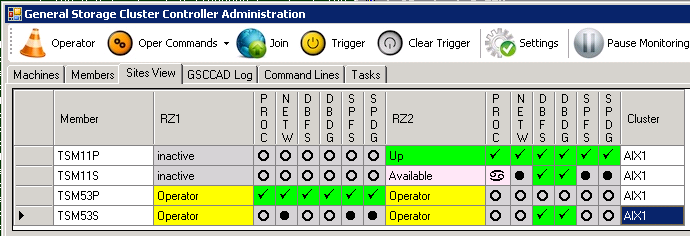
Takeover completed successfully
SAN - ISP Instance Restart
There are situations where an ISP instance can crash and the “dsmserv”-process ends. In such a case GSCC will restart the ISP instance immediately. The GSCC state cycle “Up” checks all kind of conditions including the ISP instance availability. GSCC would not leave the “Up” cycle, but rather tries to “hold” it by initiating an ISP instance start. Only if this was not successful, this member will tell the other members, that there is a problem by switching to another global state.
Of course this restart function can also be used to intentionally restart an ISP instance. So instead of taking GSCC into Operator Mode and using the starttsm and stoptsm commands, a single “halt” on the ISP instance, would stop and immediately restart ISP.
It really depends on the actual situation which way to choose for the restart. Very often it is sufficient to just restart the instance immediately (dsmserv.opt changes, hang situation, library manager refresh etc.), but sometimes there are other activities necessary before the starting ISP again (device driver update etc.). Also be aware that in a situation where the ISP instance is causing problems which results in the idea to restart the instance, it might be worth to switch into Operator Mode even if a simple restart might solve the problem. The reason is that the cause of the problem might not be clear or resolved. So even a restart would be slow or hang. A typical example would be a bad fibre channel link which causes all disk activities to be slow or hanging. With GSCC active and now restarting ISP this might result in an unwanted failover.
In this example we use the “halt” alias “stoptsm” in the ISP command line to stop the instance:
tsm: TSM11>stoptsm
ANR2234W This command will halt the server; if the command is issued from a remote client, it may not be possible to restart the
server from the remote location.
Do you wish to proceed? (Yes (Y)/No (N)) y
ANS1017E Session rejected: TCP/IP connection failure
ANS8001I Return code -50.
ANS8064E Communication timeout. Reissue the command.
ANS1017E Session rejected: TCP/IP connection failure
ANS8002I Highest return code was -1.
As explained before the member stays in the global state “Up”, but the ISP process indicator switches to “inactive”. GSCC initiates the start of the ISP. The “Up” state announces to the other members clearly that no actions are needed from their side as long as the active member is still tryoing to resolve the situation locally.
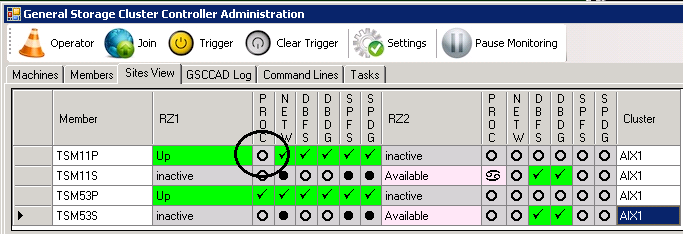
ISP Server ISP1P is stopped
The local state within the “Up”-cycle changes to “Starting_ISP”. Only in a situation where this start does not work as expected due to major problems with this instance, the global state would change from “Up” in order to involve the other members in the member team. However, that scenario is shown in another section. In this example the ISP instance start was successful.
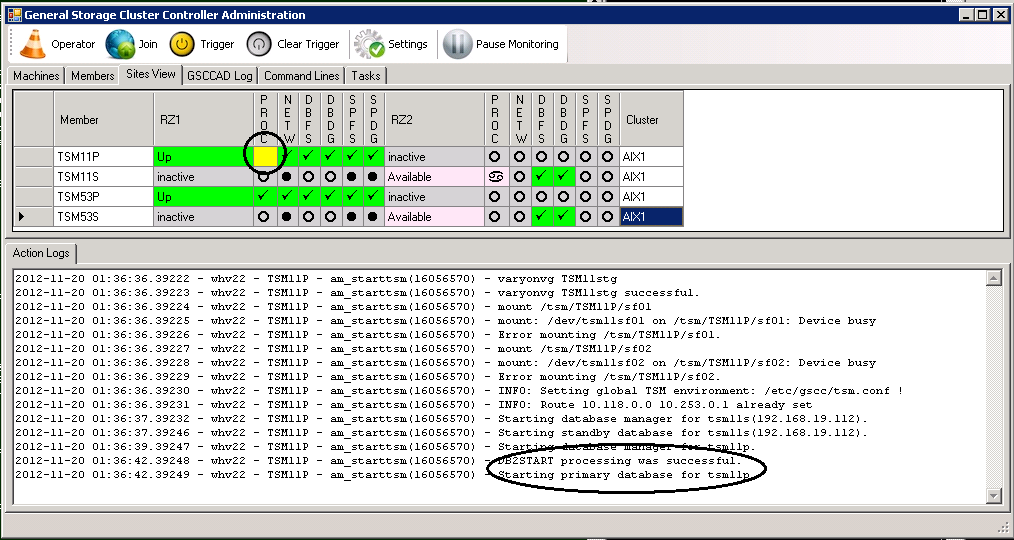
ISP Server TSM11 is started automatically
The ISP instance might not be available immediately as first the DB2 instance needs to be prepared (yellow process indicator). Finally the normal status is reached again.
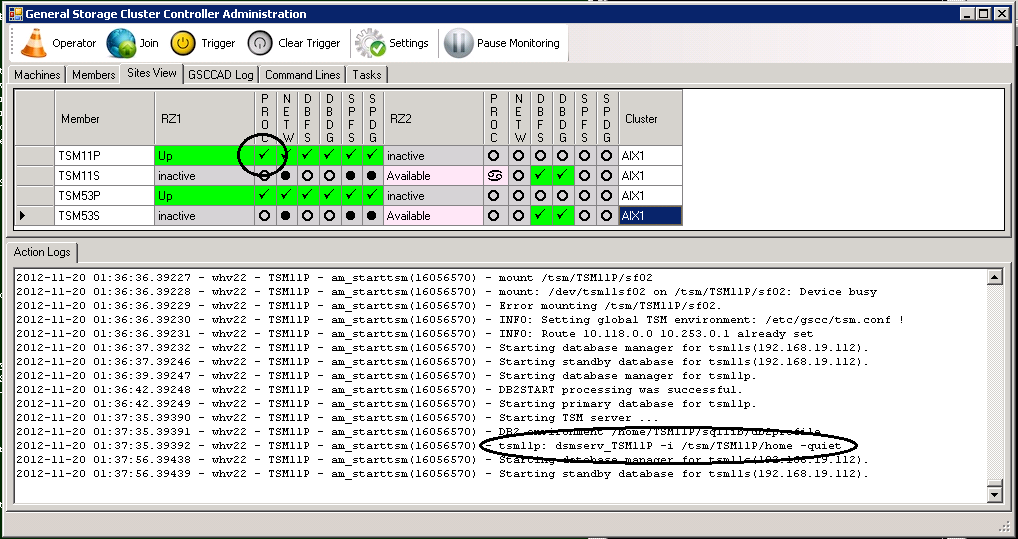
ISP Server TSM11 is started again
SAN - ISP Shared Disk Failover
A shared disk failover can be necessary in different situations. The manual takeover is one of them and was already described. The crash of a complete system is another example and will be covered in the next section. In this section a situation for shared disk failover is shown where both systems are still available but a restart of the ISP instance on the same system was not possible. This could be caused by software installation problems, DB2 instance problem with local home filesystem or IP addresses which could not be activated. As both systems are still available this is in GSCC referred as a controlled situation. This is important as the reaction can differ depending on the expert domain used. In a controlled situation with all shared disk configurations, the preferred failover mechanism is always the shared disk failover.
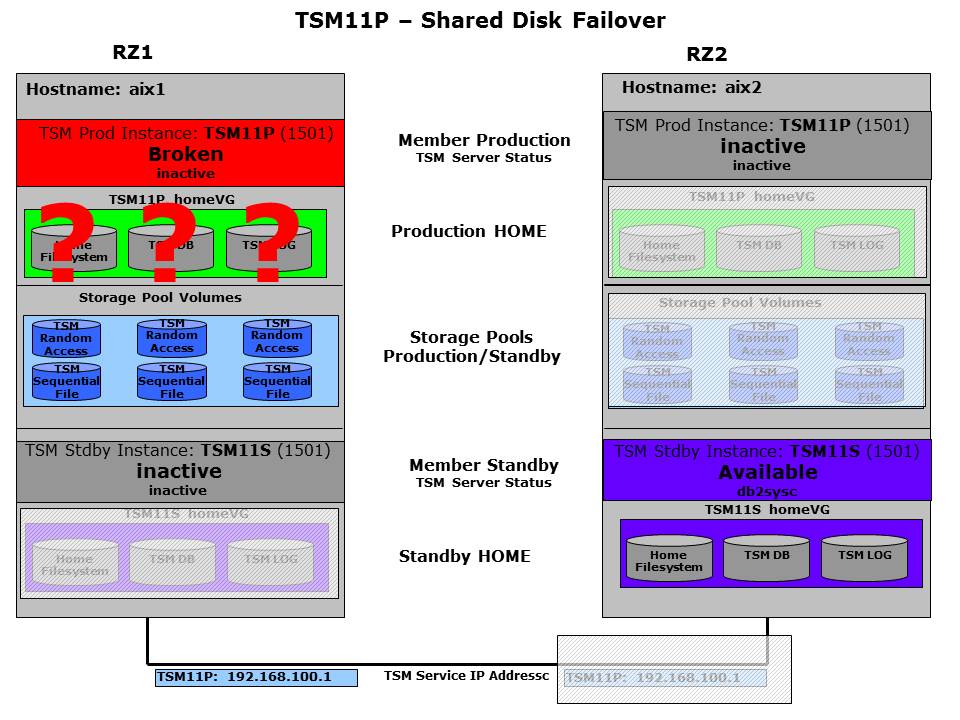
Problem with TSM11 in RZ1
The shared disk resource of the productive home member is still online, but ISP is not startable or maybe the IP address could not be activated. So while still in “Up” the member tried all local problem fixes, but did not succeed and therefore switch into the cycle “Down” and starts to clean up the resources. When that is done the stable state “Broken” is reached. This is a signal to the partner member on the remote system.
The remote member starts to activate the HomeVG first, represented by the “Down” state.
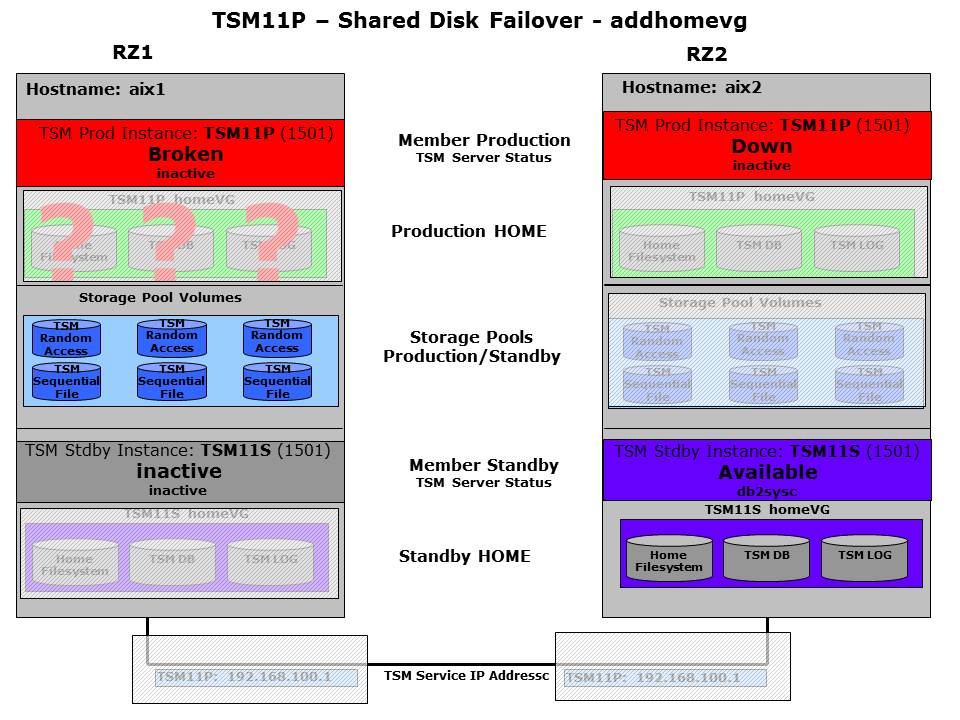
Shared disk failover – addhomevg step
As soon as this was done the member continues to the “Up” state, where finally ISP is started. When the problem was a local problem ISP would come up now.
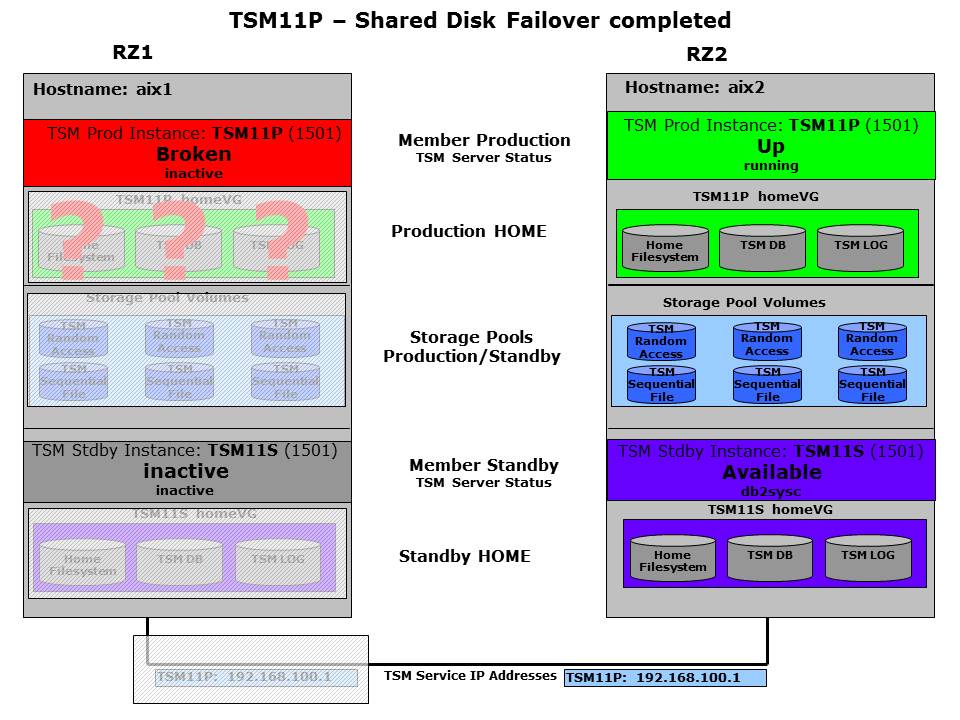
Broken – Failover successful
Shared Disk Failover
In this example we assume that the ISP instance suddenly shuts down due to an error. As in the example before, GSCC first tries to restart the ISP instance locally while still in the “Up” state. In the “Sites View”-tab the process indicator for TSM11P in RZ1 turns to inactive. GSCC initiates the restart attempt.
GSCC attempts to start ISP again
However, the attempt was not successful and a page message was sent (am_pageoper in the action method log).
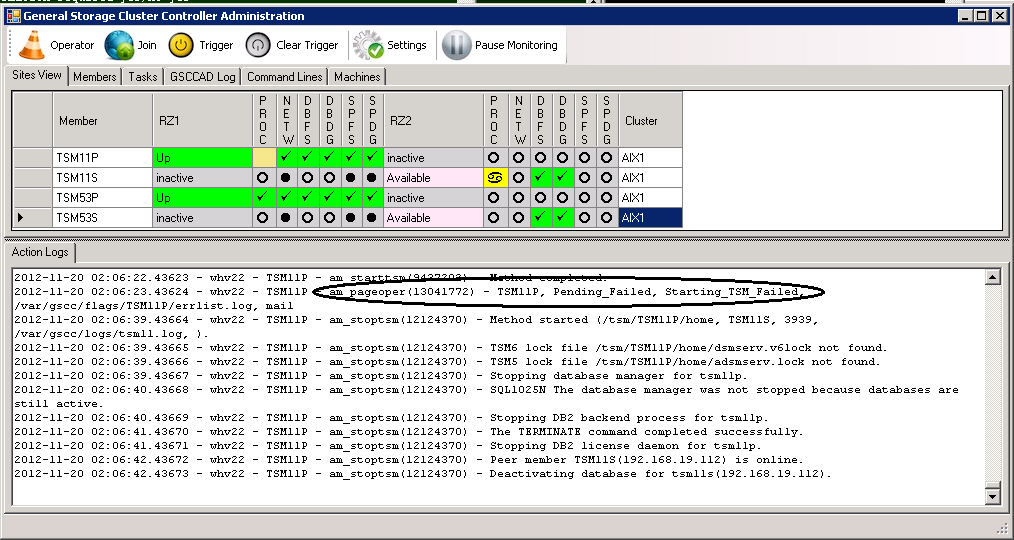
The restart attempt was not successful
GSCC will switch into the state “Down” and begins to clean up the HomeVG resources. As soon as this was done, the global state will be “Broken”. The partner member reacts on the “Broken”-state and initiates the activation of the HomeVG on the remote system.
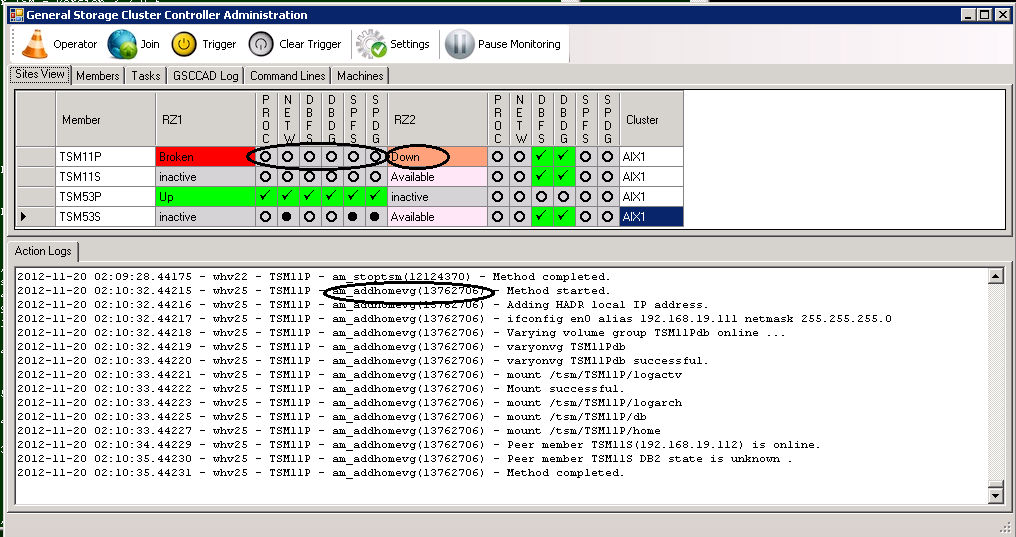
Status Broken
The activation starts during the “Down”-state, where the HomeVG is added (addhomevg step). When this was successful, the member will continue to the “Up” state, where the ISP instance is started (starttsm step).
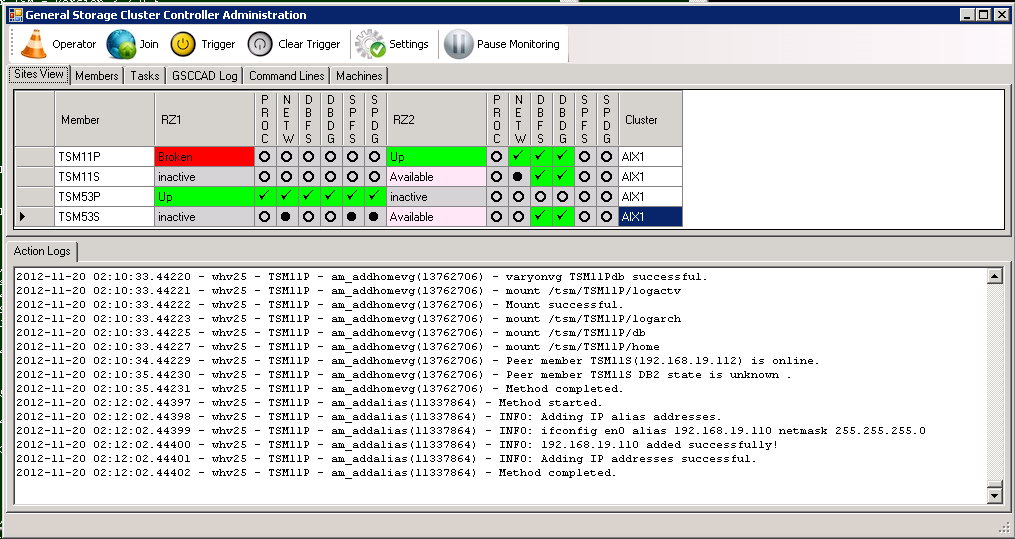
Up state reached
Currently the ISP process indicator is still inactive while preparations are ongoing.
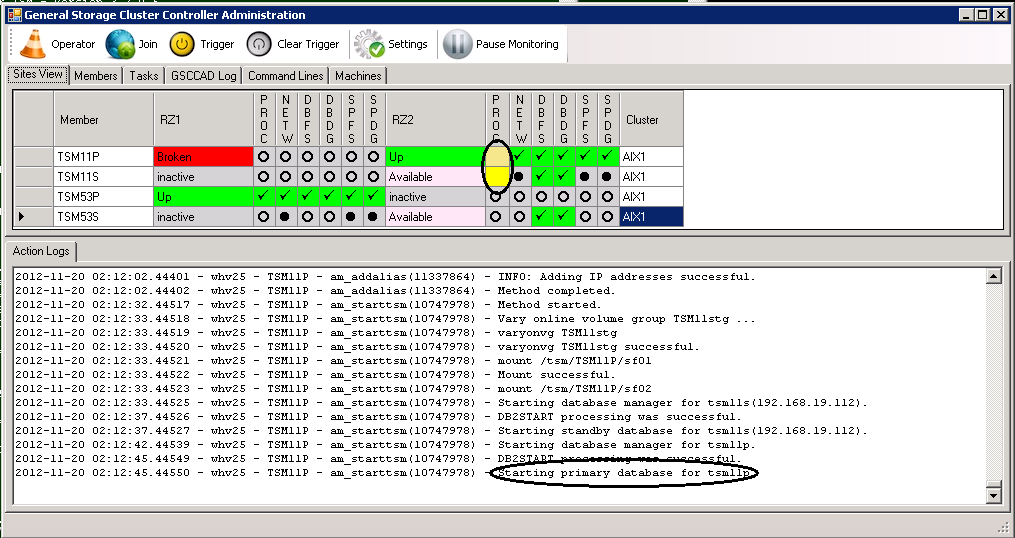
ISP Instance start is being prepared
Now the ISP instance is started and right after that the IP addresses are added.
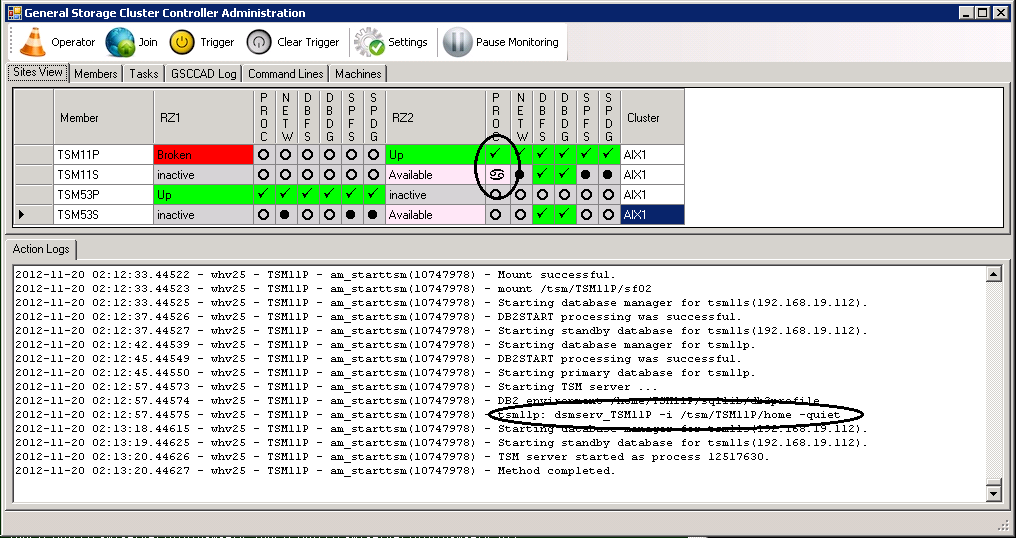
ISP instance failover completed
Cleanup Error State
In this example the failover to the other host was successful. Now the error situation on the original host has to be analyzed. When the cause of the error was found and it could be resolved, the cluster state has also to be cleaned up. This is done in two steps. First the complete member team is brought into Operator state. Be aware that the the member in state “Broken” would not follow the other members in this case, so please ensure to select all members and request the Operator state. The reason for that is to avoid a situation where the “Broken”-state is left unintended, although the error cause was not really fixed. The second step is to clear the “trigger”, which is the indicator for that error.
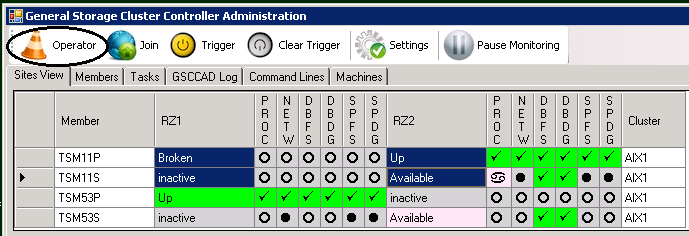
Operator Mode requested including “Broken” member
Requesting Operator Mode
As soon as the Operator Mode is enabled, there is a “TRIGGER” button available. The intention of this button is to force a cluster reaction which was set to manual before. In this case there was an automatic reaction and it was needed to manually use it. However, the trigger situation (q trigger) still documents the error situation. By clearing this trigger the correction of the error situation is confirmed. This is done by selecting the member and clicking the “Clear Trigger” button.
ISP Instance Failback
In this section the failback after the shared disk failover is explained. As the steps are basically the same as during the manual failover only the most important screenshots are shown.
Currently we are still in the Operator Mode. So we can directly use Operator commands and deactivate the ISP instance on the remote host.
Failback - deactivate
And then on the home system the activate-command is requested. This is only the confirmation window:
“activate”
Finally the cluster is joined again and the status is back to normal.
Failback finished
SAN - ISP Standby Failover
Since HADR is supported the standby failover has different role on the GSCC cluster. With classic sync where the database is further behind the primary this failover was always only the second alternative as it could mean loss of some backup transactions. That’s why the standby failover always required a manual intervention. With HADR and the possibility of nearsync or sync configuration this has changed. An automatic standby failover is supported. This is especially true for the IP only cluster configuration. However, even in a HADR expert domain with primary shared disk failover the standby failover is a manual operator step.
In this section the operator intervention based standby failover is described. We assume that the shared disk failover to the other host was already performed by GSCC automatically, but the problem could still not be resolved. The ISP instance startup was unsuccessful even on the remote host. If we look to the state charts, we see that the “Broken” state was set for the local primary member.
Productive instance has a problem – VG Failover will be initiated
The cleanup was successful and the “Broken”-state was reached which initiates a state change for the partner member on the remote host. This will be “Down” in the first step for adding the HomeVG. The next figure shows that the partner member afterwards changes to the “Up”-state which attempts to start the ISP instance.
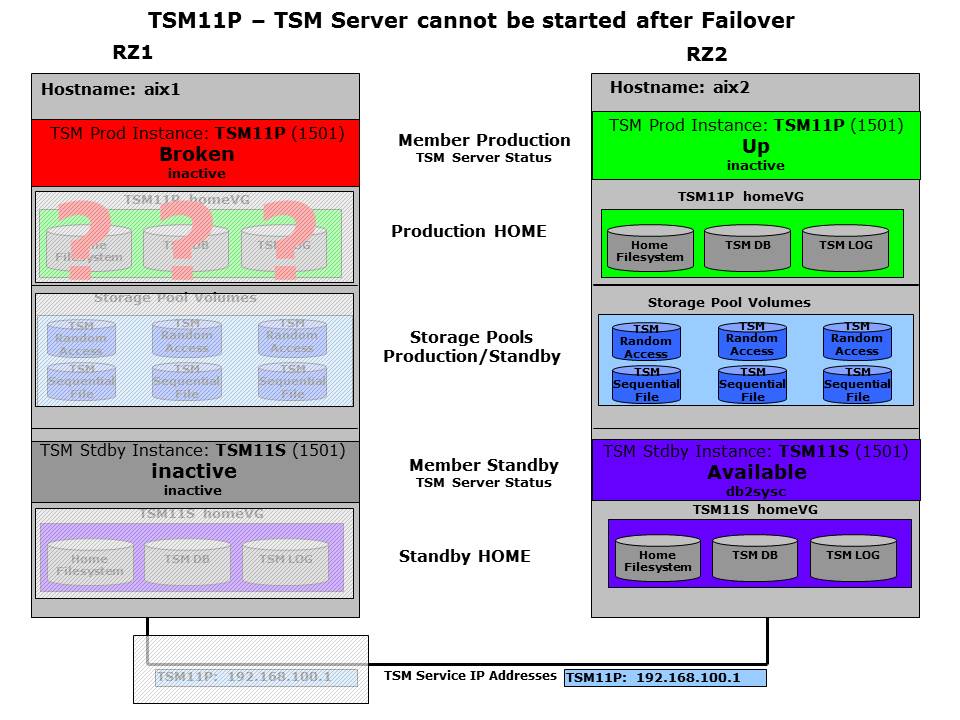
Cluster attempts to activate ISP Server on the remote Server
In this example the start does not work on the remote host either. So the “Up” state cannot be fulfilled. Therefore the next step is to return to “Down”. Depending on the configuration this can lead to another restart attempt or it would stay in the “Down” state.
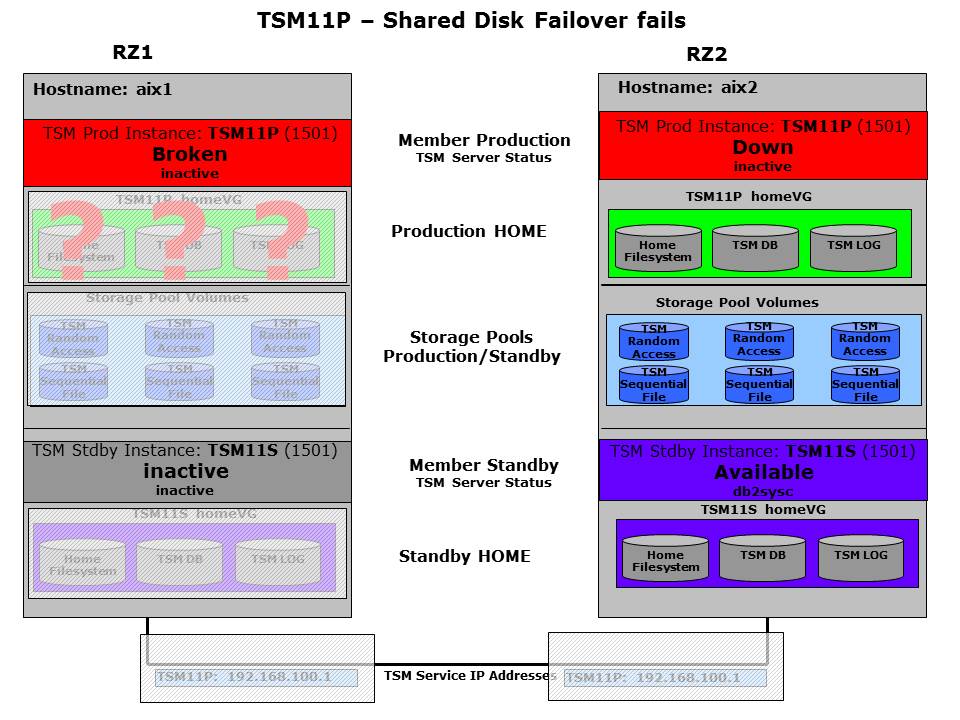
ISP Server Restart after shared disk failover fails
GSCC will send a paging message to the administrator (am_pageoper) in this situation. Also a trigger was set for this member. Just by confirming the error situation for the member TSM11P in RZ2 the standby will react. This is done by selecting this member in the GUI and using the “TRIGGER”-button. The trigger condition will cause a state change to “Failed”, which is in contrast to “Broken” now giving a signal to the peer member rather than to the partner member to get involved. As soon as the peer member is “Failed” the member for the standby database will go to the state “Up” performing a failover. Depending on the configuration this can be a recovery and commitment of a database which was synced the classic way or it will be the HADR failover.
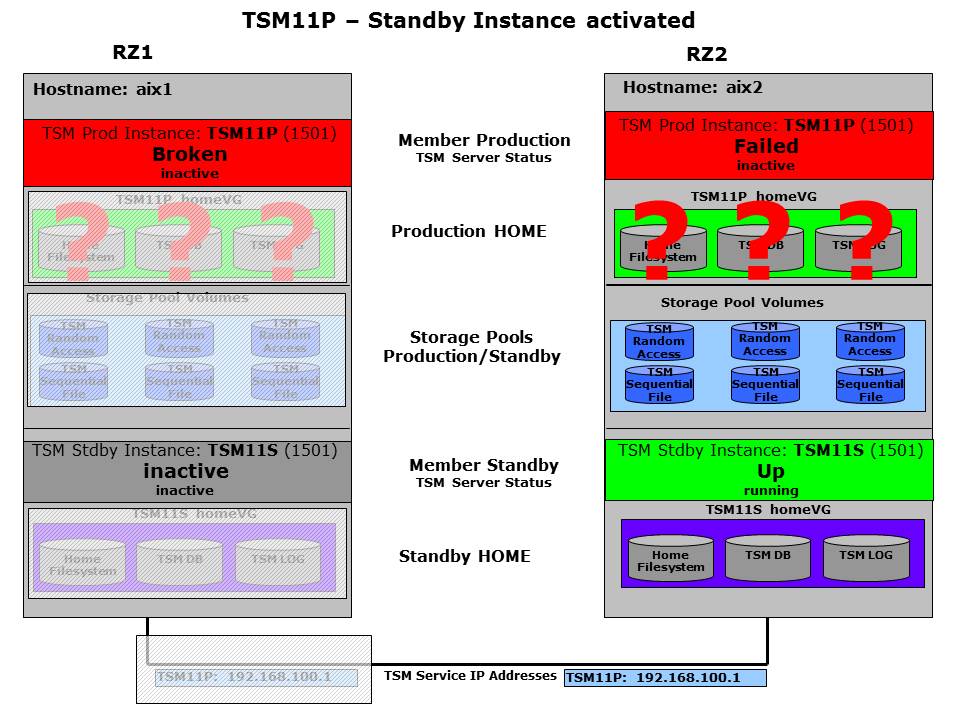
Operator “TRIGGER” activated standby instance
SAN - System Crash – Shared Disk Failover
This scenario describes the situation where a complete system is unavailable. The description focus on a single ISP instance as GSCC is an application based cluster. However, be aware, that during a system crash the same procedure will be followed for all ISP instances which ran on the failing host and all the more that the surviving instances on the other host will lose their standby database in case of an HADR configuration. Although it is configurable, the common configuration would not perform an automatic failover for the standby instances. There are two different expert domains for the system crash situation. This section will cover the expert domain with shared disk failover as the primary reaction on a system outage, while the next section will cover the HADR failover expert domain. In this example we assume that one system is not reachable at all including heartbeat. In case the system would only be isolated and is not really down, the isolated ISP instances would be stopped, to ensure that the instance is not activated on two hosts which were just split.
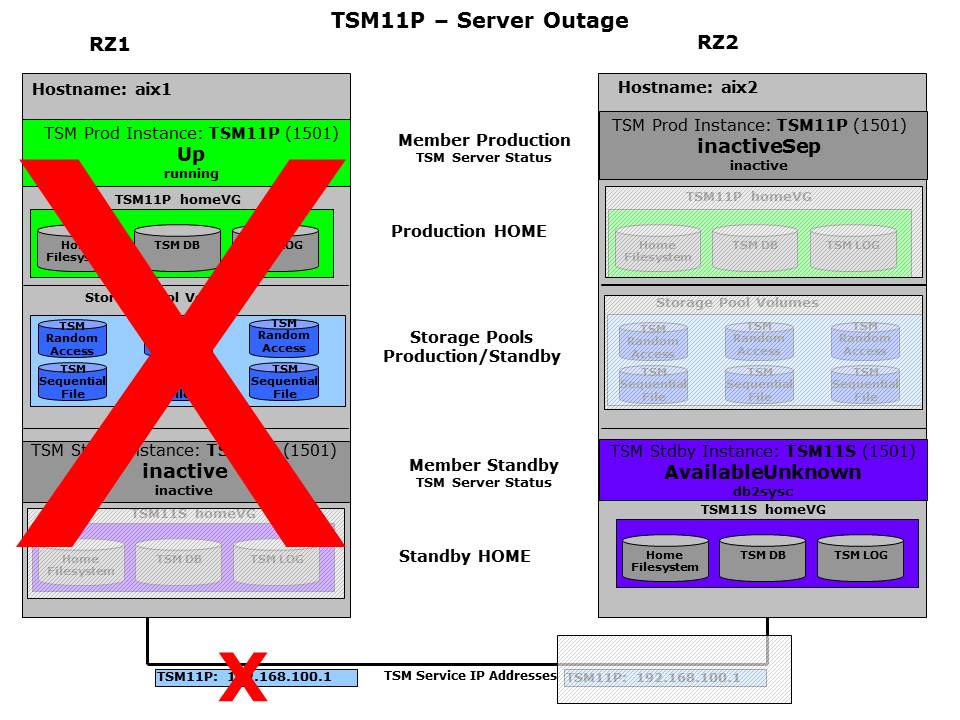
System crash
With this expert domain the partner member will react on the unaviable remote system. After initially switching to “Down” to activate the HomeVG the partner member will go “Up” and start the ISP instance.
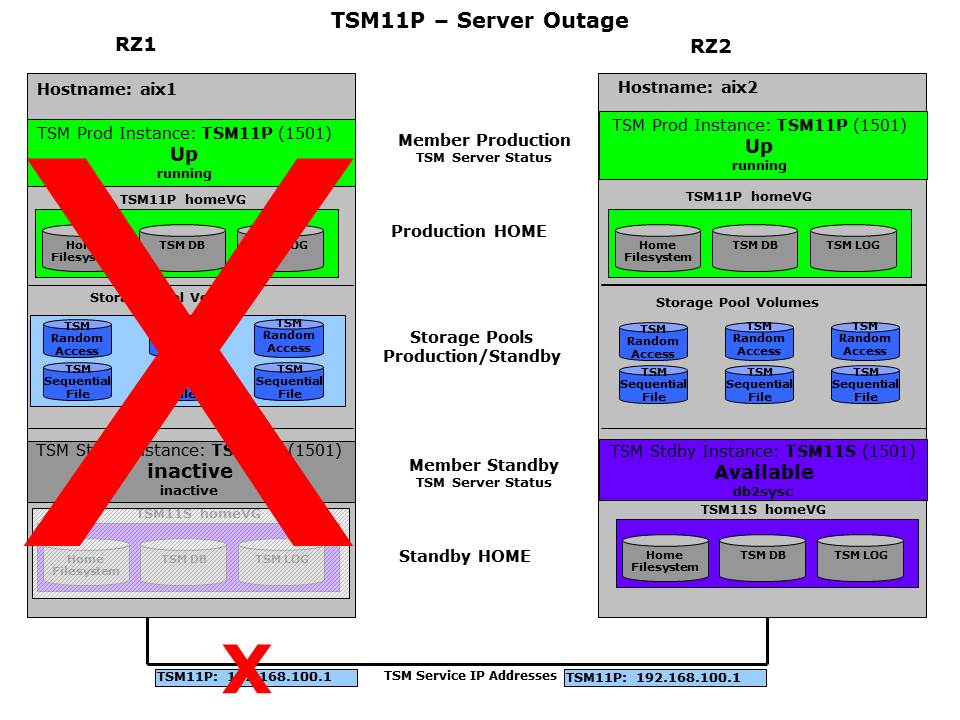
Failover successful
In this example the AIX system “whv22” is not reachable. This is immediately visible in the GUI in the “machines”-tab, but also in the “Sites View”-tab. Of course the reaction in “machines”-tab can have several reasons as it only means that the communication to that host is lost.
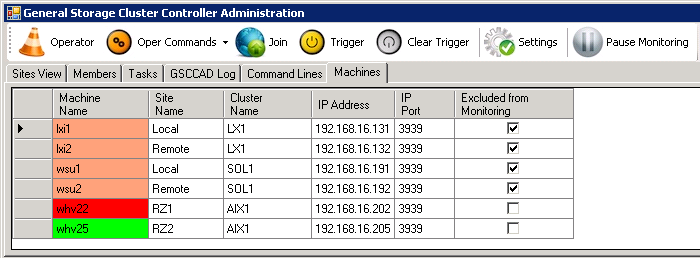
Server not reachable
The “Sites View” will provide further information, as the partner member TSM11P in RZ2 would check all conditions and if necessary leave the “inactive” state in case the failover is required.
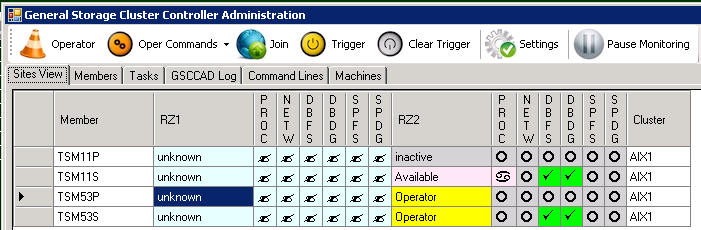
Server down
In the next screenshot the local state is already in “inactiveSep”, but still checking the remote status.
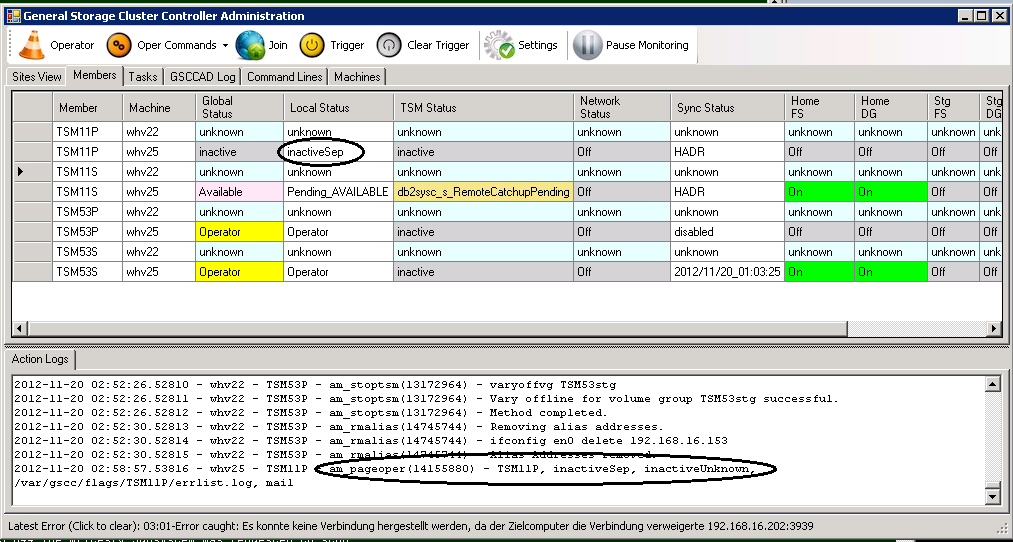
inactiveSep
After further checks including heartbeat the member TSM11P on the surviving system is leaving the “inactive” cycle and switches to the global state “Down”. This is the first step to add the HomeVG (addhomevg). When this was successful, the next visible global state will be “Up”. Now the ISP instance is started.
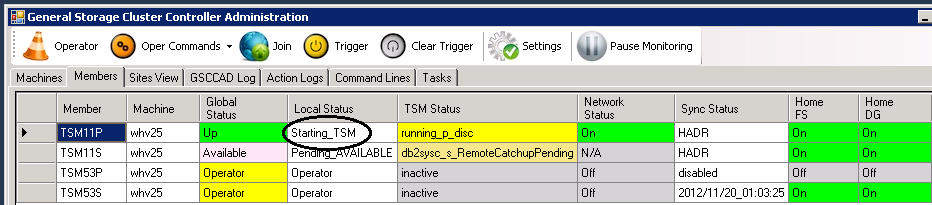
ISP is starting
The failover was successful, now only the standby, which was running on the surviving system needs to be synced into peer. During ISP startup it can happen that the standby loses connection. However, GSCC would restart the standby while in “Available”.
ISP is active
SAN - System Crash – HADR Failover
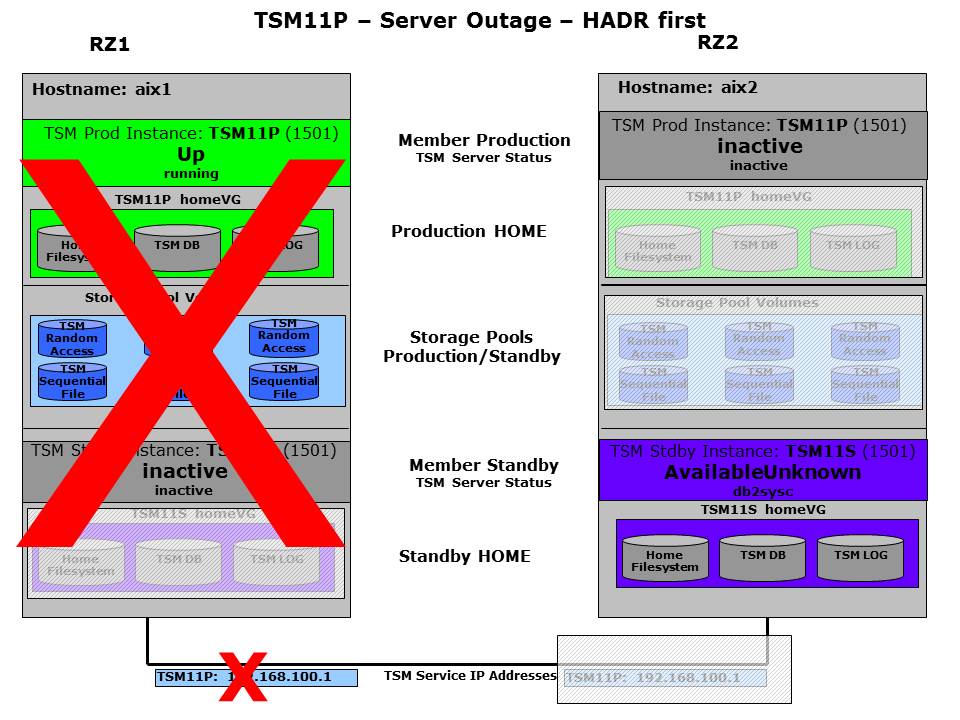
In an HADR setup with shared disks a server crash can be resolved in two ways. The first option is to attempt to activate the disks of the primary database by force on the remote hosts. This was described in the previous section. Option two is to activate the independent synchronized standby database instead. This option is explained here. Both options have their distinct benefits. The discussion about that is beyond the scope of this section. However, it is important to understand that the option is chosen by the GSCC entity called expert domain. By using a different expert domain it is possible to change the cluster behavior. No other changes in the ISP or GSCC configuration are required.
In GSCC the system crash is considered an uncontrolled situation. This means that certain members are not available and the decision has to be made on local inputs only.
When the remote system is unavailable both member in RZ2 for TSM11 will realize the problem. In contrast to the previous scenario, there is no reaction on the partner member, but on the peer member, which is TSM11S in this case.
Server or LPAR crash
The member will after further checking and ensuring the other system is really unavailable switch to “Up” to begin the ISP startup. Please note that compared to the shared disk failover by the partner member before, there is no “Down” step in between needed as the HomeVG for the standby is already activated here. To ensure that the remote system is really down a heartbeat and a client IP quorum is used. So if the local system is not really down but only isolated, the state model would stop ISP when the client IP quorum is not met. Of course the client IP quorum is also checked before the “Up” state is reached on the standby system. During startup GSCC will detect that a DB2 HADR takeover is required to turn the standby database into a primary. To ensure consistency the automatic takeover will only be started as long as the database are in the peer window. As ISP always restart DB2 itself, HADR will be stopped in this case to ensure ISP can be activated. If the failing system did not take real harm the previous primary can be reintegrated into the HADR cluster as standby later and HADR can be activated on the currently active system. Be aware that the reactivation of HADR currently requires manual intervention. In order to resolve the situation it is recommended to use the Operator Mode.
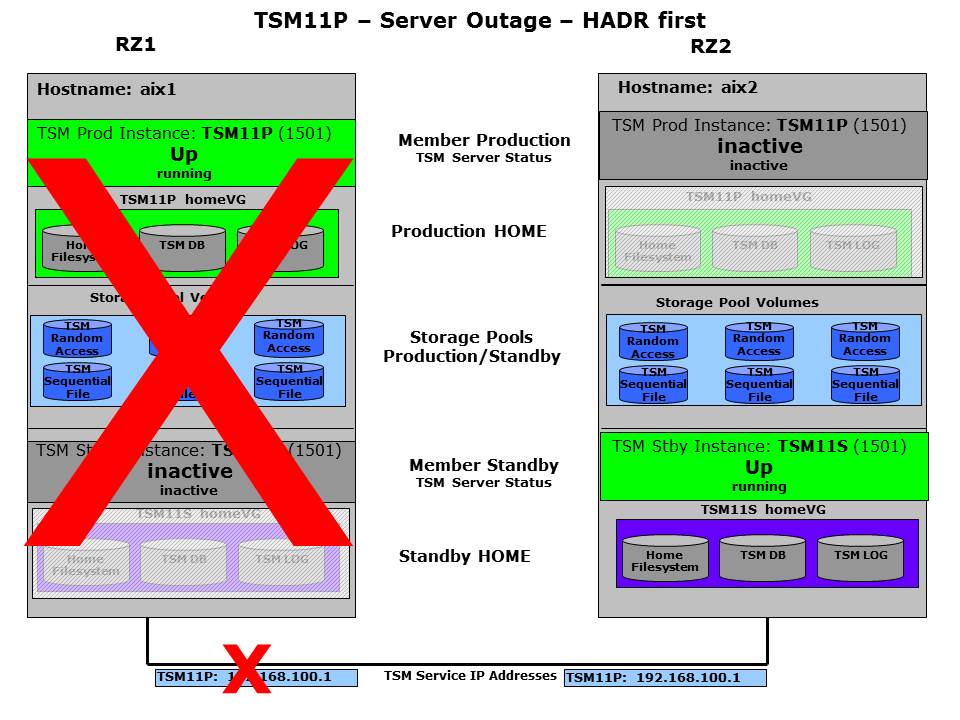
ISP activated on standby database
IP-only Configurations
This chapter covers common Operator tasks especially for clusters with IP only failover configurations. It provides step by step examples for the different situations. The different activities are performed with GSCCAD, but all of them could also be performed with the command line interface “gsccadm”. The following scenarios are covered. All the examples are based on the expert domain “edUNIX_T6_HADR”, which contains the ruleset for the HADR based IP only cluster configuration.
IP - ISP Starting Point
The following chart shows a typical setup for a GSCC HADR cluster. The ISP database and log filesystems are located on internal disks. The ISP storage pools are using NAS disks and physical tape libraries. There are two active ISP instances (TSM86/TSM87) which are synchronized via IP by GSCC and DB2 HADR. The active ISP instance is running on the primary DB and the inactive copy of this database is referred as the standby database. This setup is the starting point for the upcoming scenarios described in this chapter.
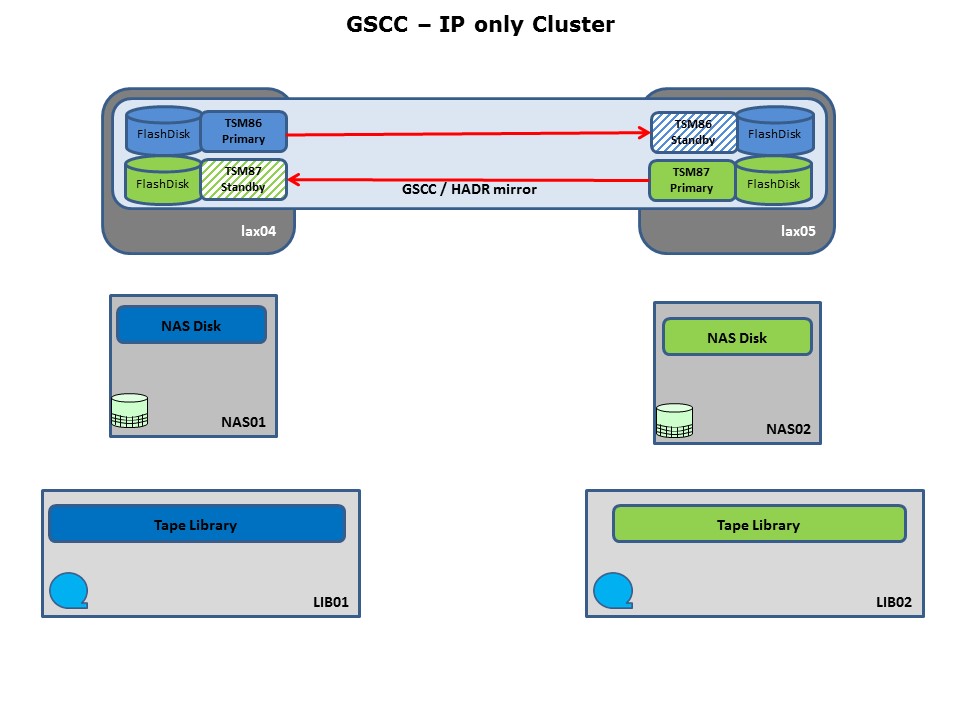
IP only cluster setup example
From GSCC perspective the primary and standby databases are controlled by member definitions. In this setup there are two members for every ISP instance, one per host. The next chart shows the member status for the ISP instances in the normal operating mode. In contrast to the shared disk scenarios explained before, the disk resources are always online. GSCC controls which database is active (primary database) and where the ISP process is running and IP addresses are set. In normal operation the other database is available (standby database) and is applying log files shipped from the primary database. The storage pools are in this case also connected via IP (NFS) and are therefore already available on both systems.
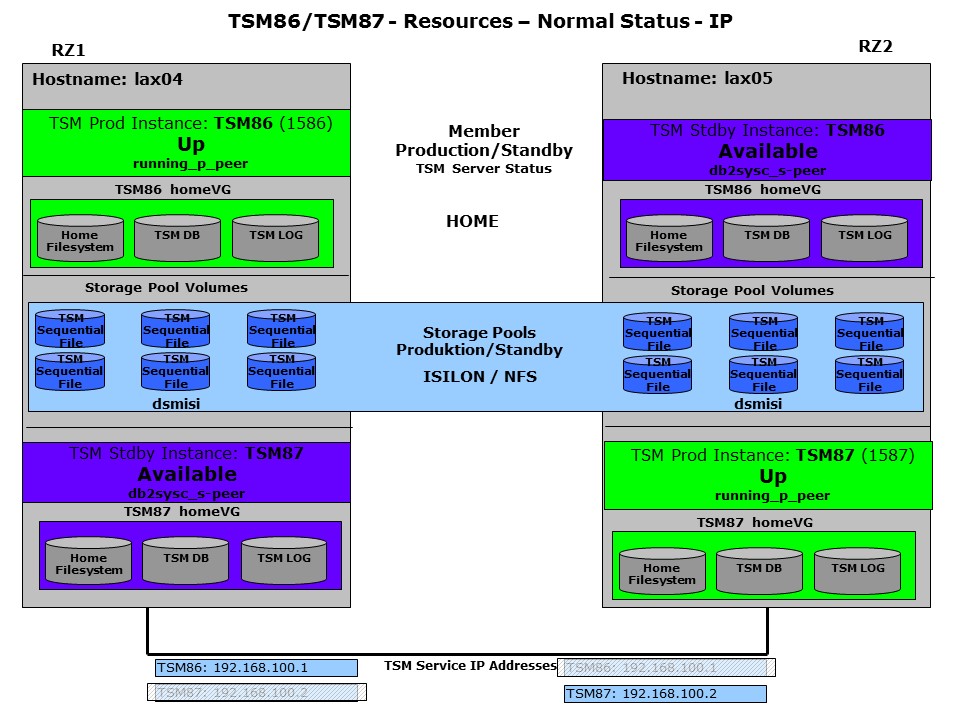
Member status – starting point
GSCCAD
In case the cluster in a normal state, the GUI “Sites View”-tab would look like this. You can mouse-over to see the detailed status of the process (PROC), the home VG and filesystem should always be online (DBFS). By clicking the right mouse-botton the view can be expanded to show even network and storage pool status.

GSCCAD – normal status
gsccadm
In the command line interface “gsccadm” the status would look like this. Be aware that gsccadm returns the local status on the host where it was started.
gscc lax04>q status
150430081345 TSM86 Up
150430081400 TSM87 Available
gscc lax04>q tsm
TSM86 running_p_peer
TSM87 db2sysc_s_peer
However, you can use command routing to get the status from the remote host.
gscc lax04>lax05:q status
150430081345 TSM86 Available
150430081400 TSM87 Up
gscc lax04>lax05:q tsm
lax05 returns:
TSM86 db2sysc_s_peer
TSM87 running_p_peer
IP - ISP Instance Maintenance
As the activated cluster will react automatically on certain changes it is important that with maintenance situations such as system reboot, ISP changes or network changes the cluster automatics are temporarily disabled. With GSCC this is done by switching the member’s status to “Operator”, so the cluster is in “Operator-Mode” before starting any maintenance activities. While automatic functions are disabled the “Operator-Mode” supports GSCC logics to start and stop ISP, move ISP instances to the other hosts and more. The GSCC logic will take care of all required steps including DB2 and HADR handling, so it is even recommended to perform these actions by using GSCC operator commands instead of executing these steps manually.
Operator Mode
The operator mode needs to be requested through GSCCAD or gsccadm. All members in a member team (all members controlling one ISP instance) will follow into the “Operator” state as soon as on member was set to that state. In the HADR only configuration there is one member on each system for a ISP instance. In this chart both ISP instances TSM86 and TSM87 are shown with their member status und the resources. In this example we will set both member teams into the Operator status. The resources stay unchanged of course. In the following chapter you can follow some of the typical maintenance tasks which can be performed when GSCC is in Operator Mode.
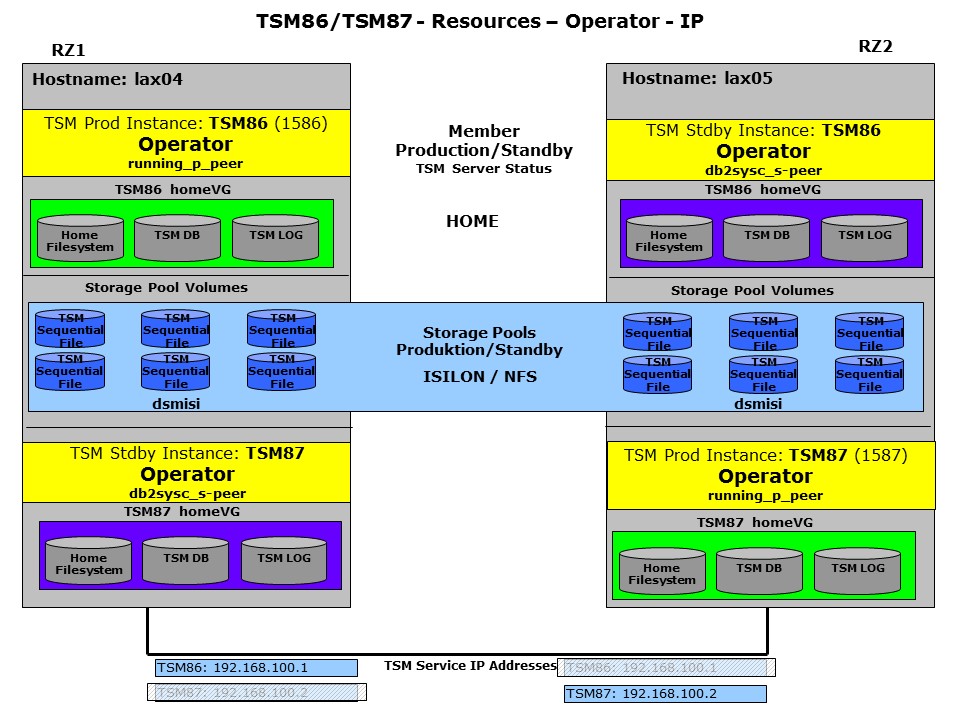
Operator Mode
It is best practice to select all member status fields in GSCCAD using shift to allow multiple selection. Then the Operator button is used.
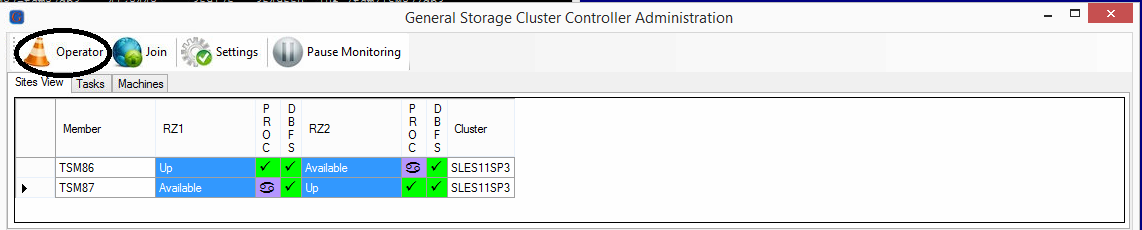
Operator Mode request
As with all GSCCAD commands a confirmation window appears with a list of members and its current status. In this case the command is “enable operator”. The command will be executed for all 4 members. As this is a request it might take some time until all members have reached the expected status.
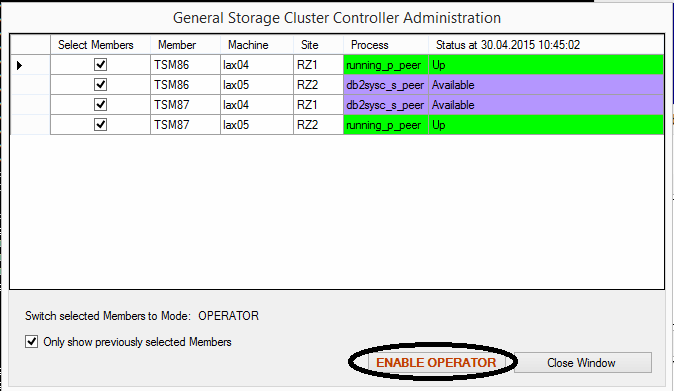
Enable operator for all members
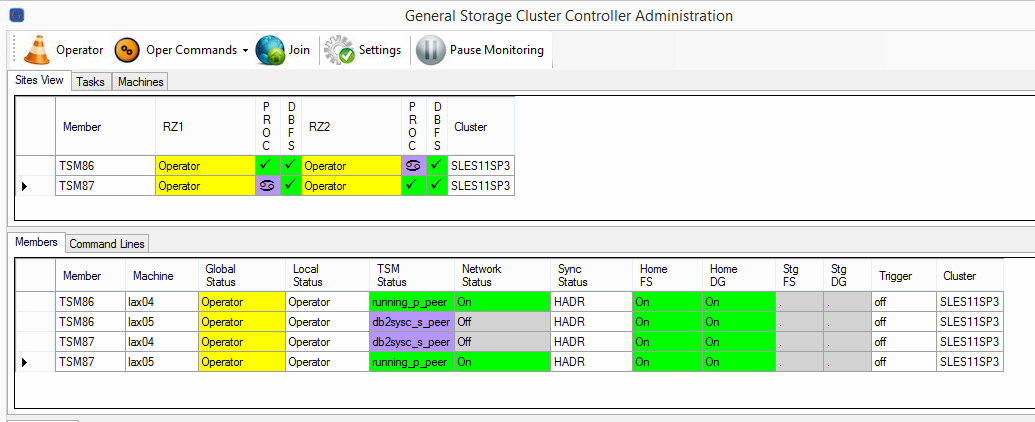
All Members are in Operator State
When all members are in Operator state, the maintenance activities can start. In order to stop, start or takeover ISP the GSCC Operator commands should be used. After the maintenance work is done, the cluster automatics are activated again by using the Operator Command “Join”. During the Join the current status of HADR and ISP is considered and the cluster states reached accordingly. In this example, there were no changes, so the previous status is displayed again.
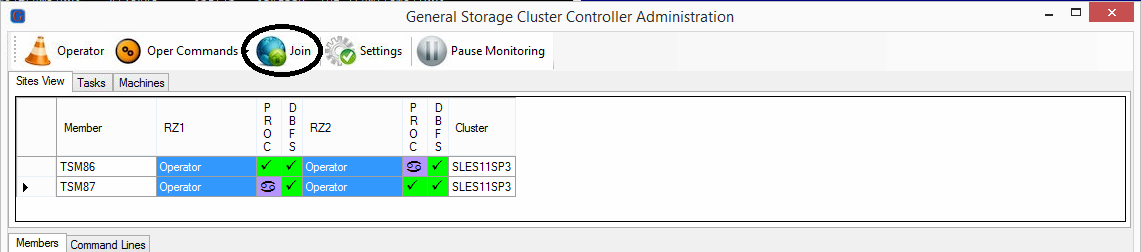
All Members need to be selected for the “Join” Command
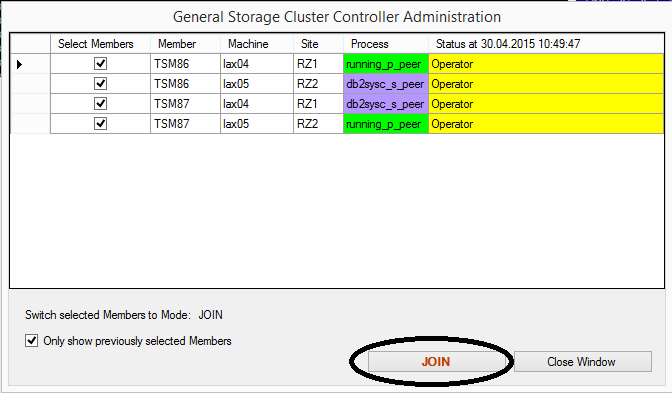
The “Join” Command is confirmed for all Members
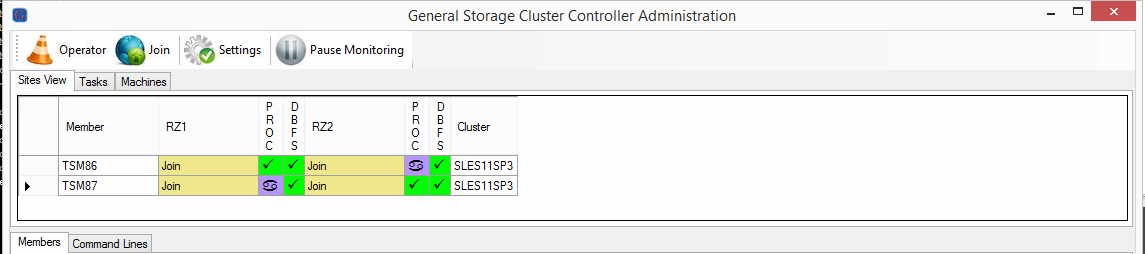
All Members are changing to the state “Join”
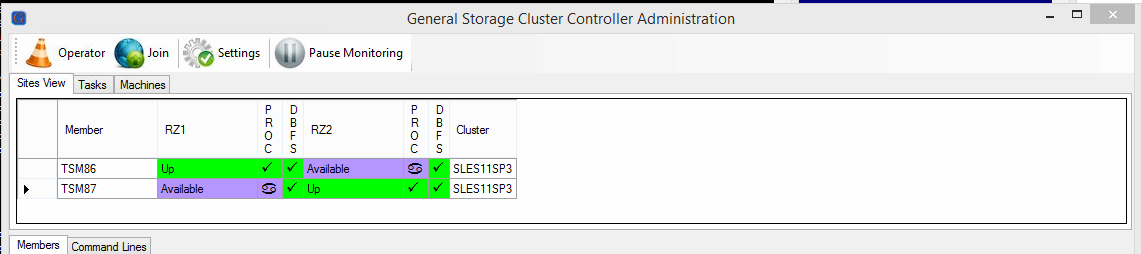
All Members are back to the normal States again
IP - Planned ISP Takeover
To move a ISP instance to the other server, GSCC needs to be set into the Operator Mode as described before. The GUI would then show this status:
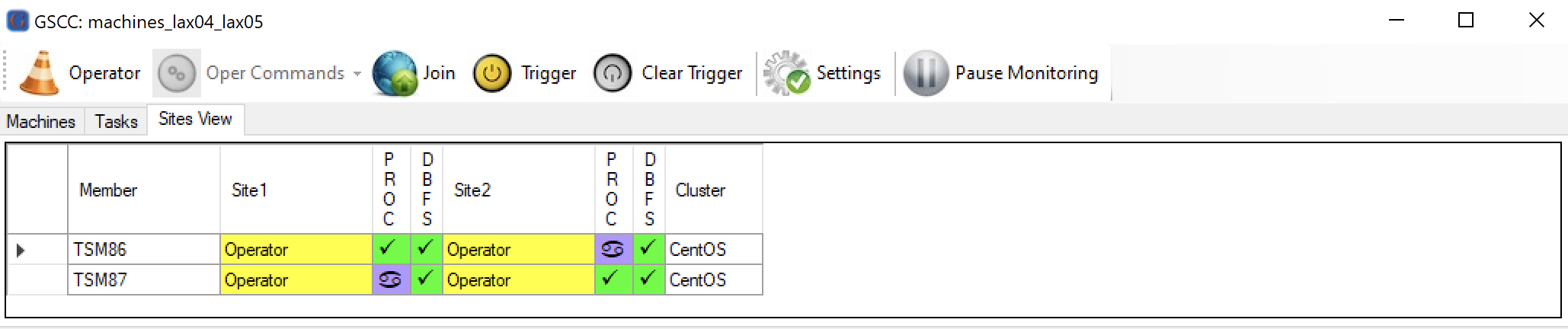
All Members are in “Operator”
To perform a takeover, we use the “Switch SP/TSM Services” function in GSCCAD, which will first stop the ISP instance on the active site, then perform an HADR takeover and finally start the instance on the inactive site.
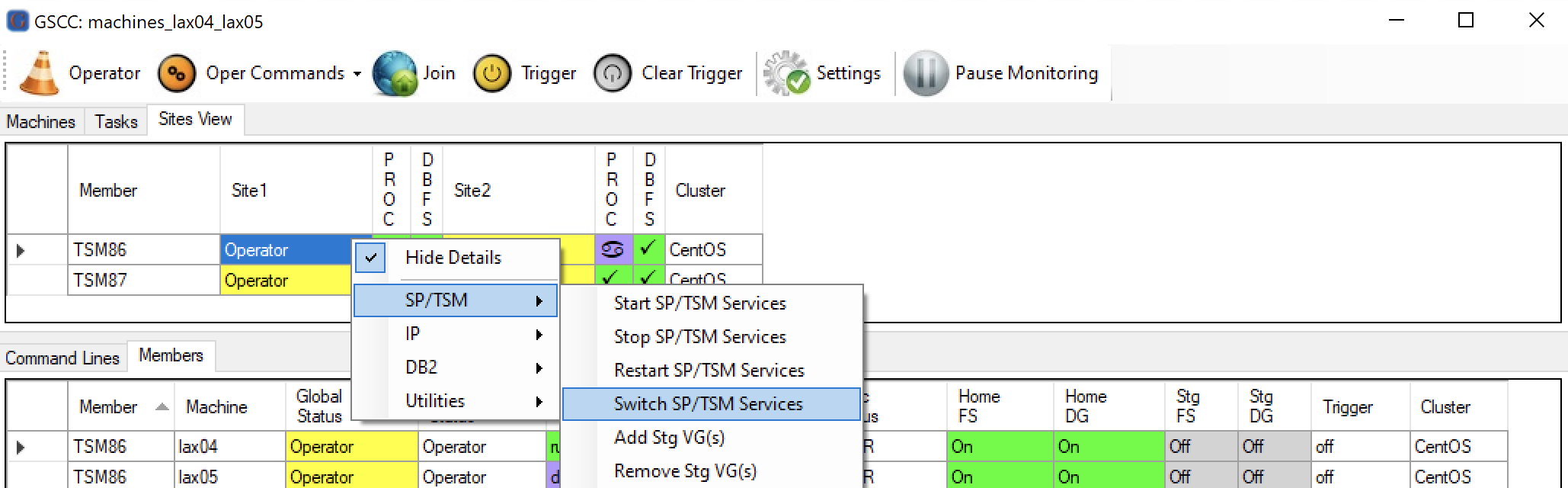
Select a member of the instance you want to switch, then click “Switch SP/TSM Services”
Now a confirmation is requested that the ISP process is in the “running_p_peer” status and we plan to switch this instance.
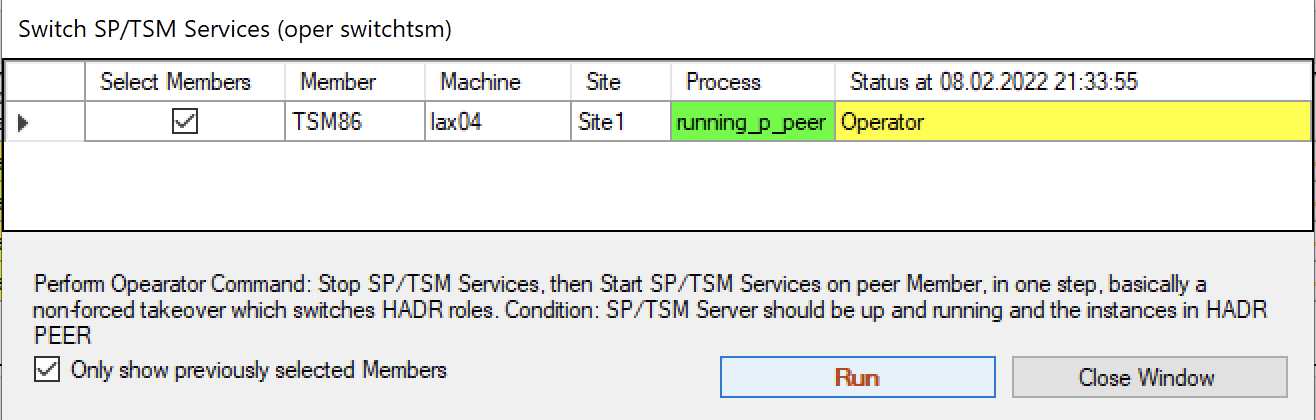
Confirming the switch operation.
GSCC now will start to stop the ISP instance. It will also take care of other resources like storage pools, IP addresses and will also ensure that HADR is stopped properly.
The “Local Status” in the “Members” tab shows that we issued the command to switch.
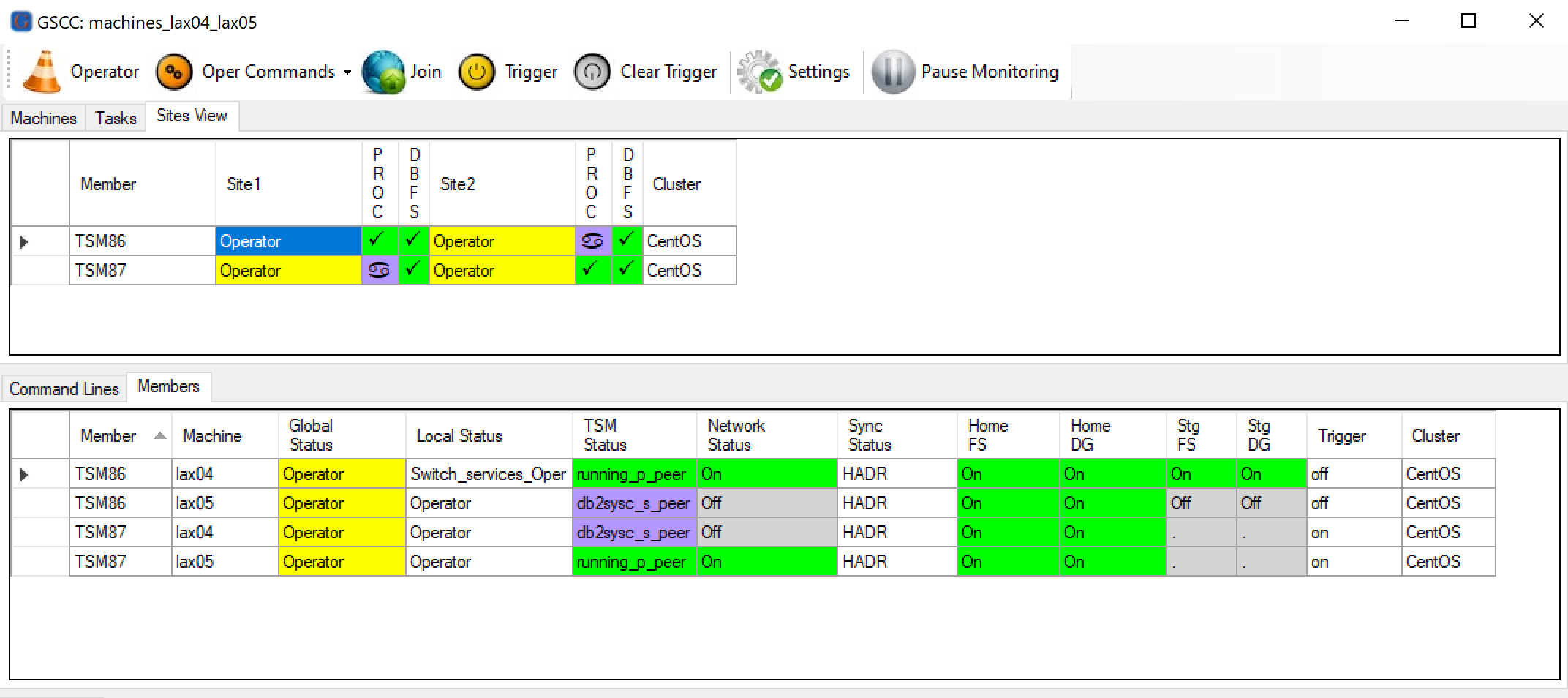
“Local Status” shows Switch_services_Oper, meaning that the switch tasks are about to start.
Check the “Action Logs” tab to follow the current state and ongoing GSCC tasks.
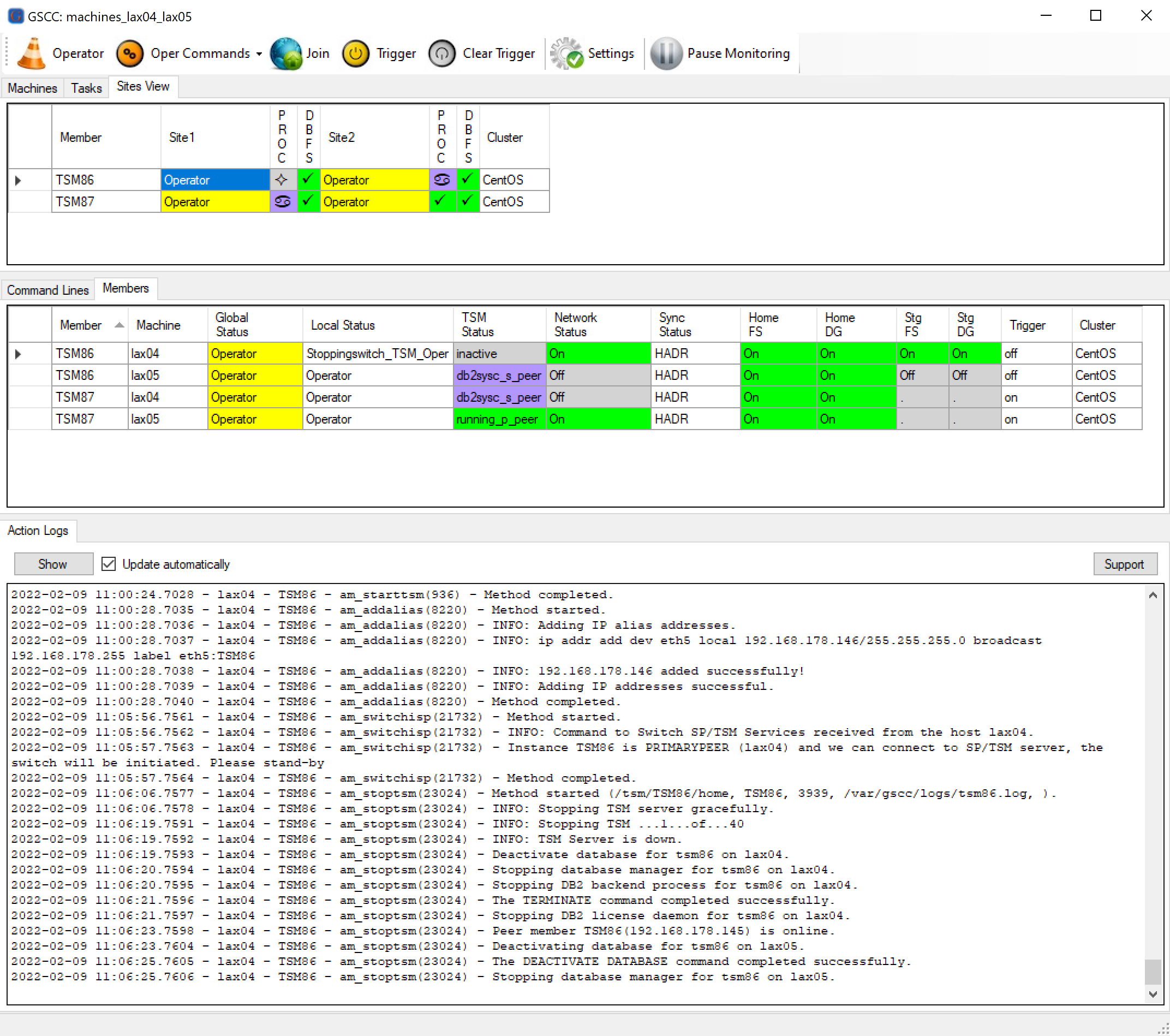
The action logs show that ISP is shutting down on machine “lax04”
When the ISP instance is stopped on lax04, the storage volumes are deactivated and the service IP is disabled.
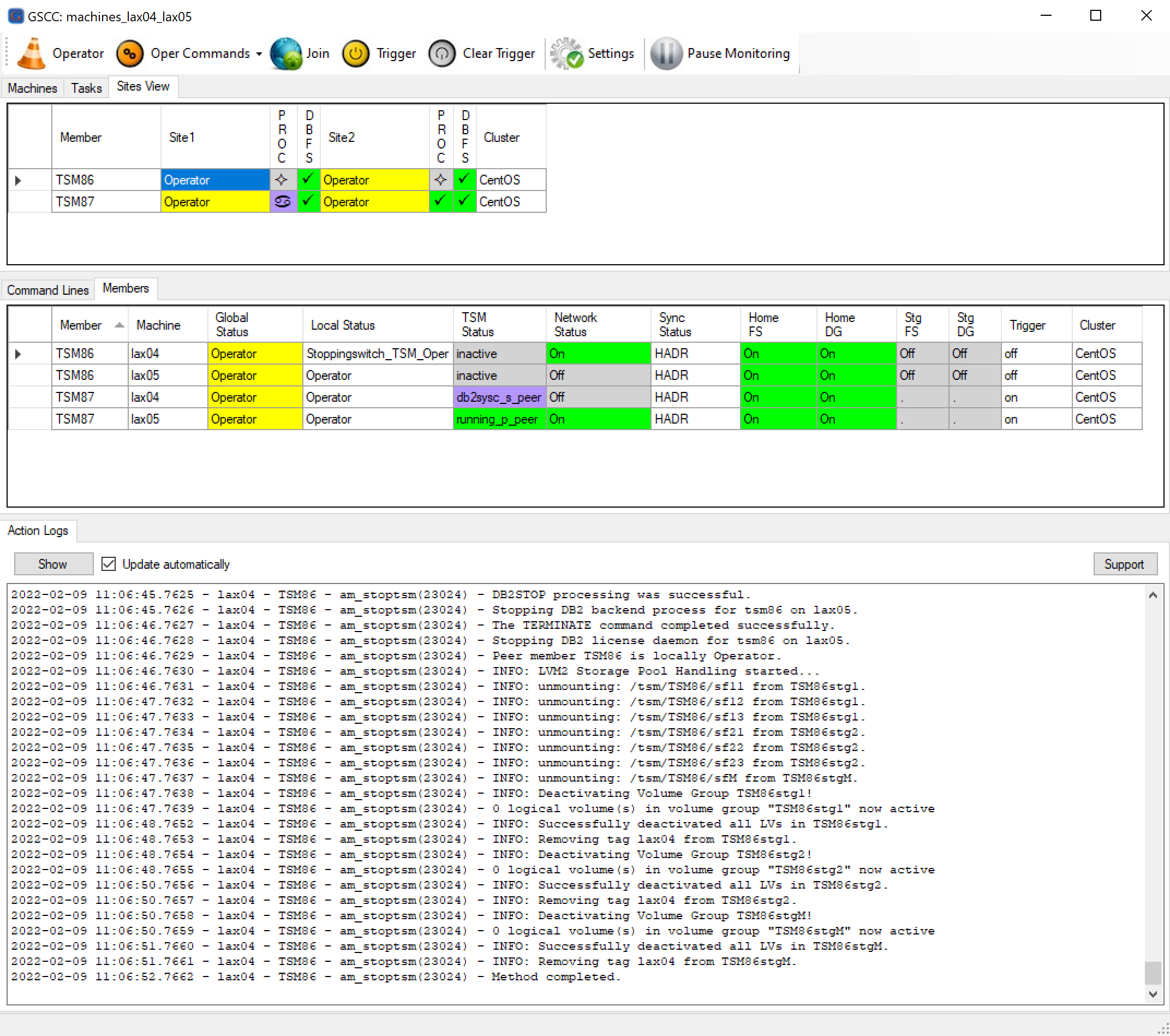
GSCC has completely shut down the ISP instance and the configured resources.
Now the ISP instance will be started on the other server.
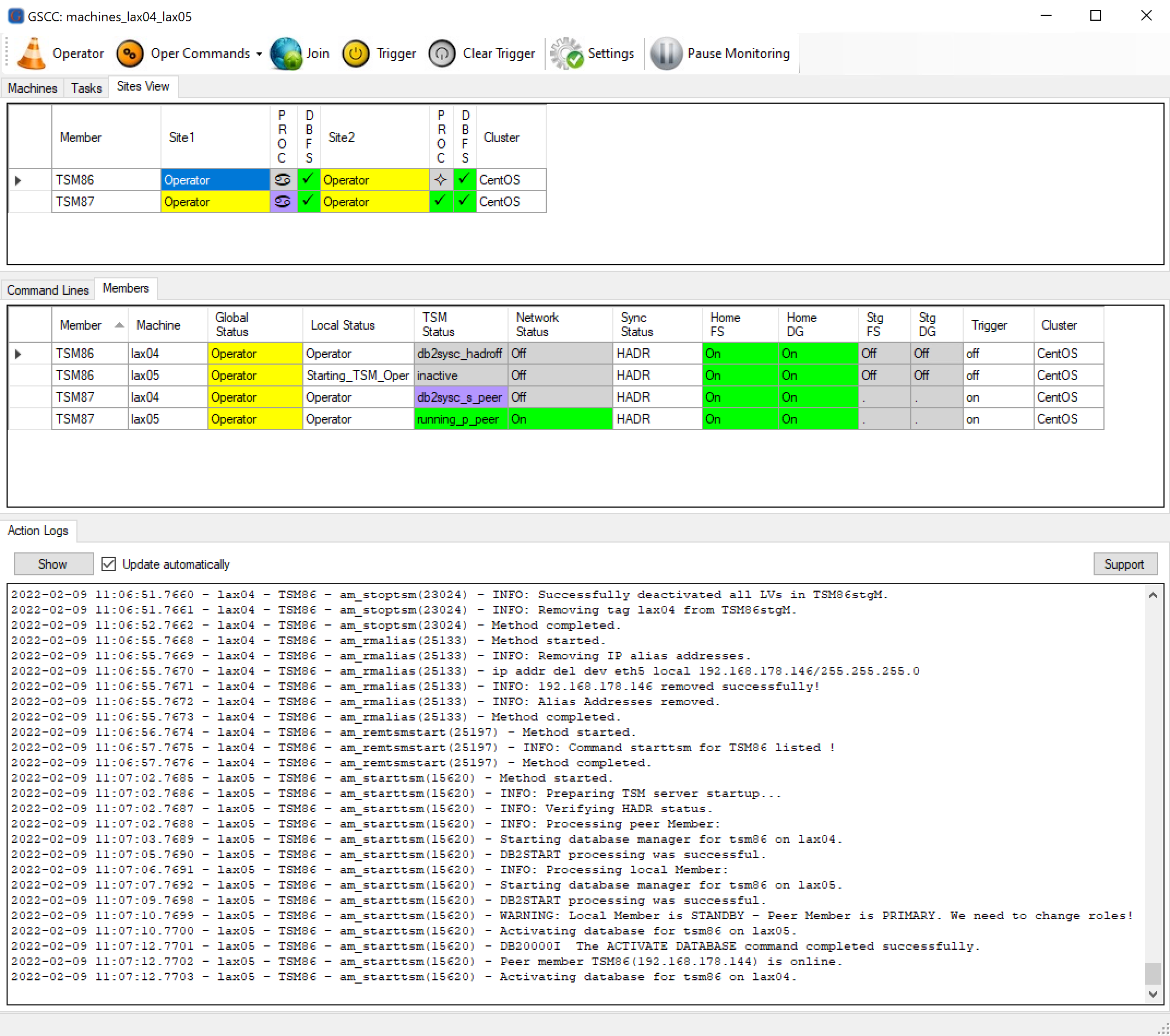
Starting ISP on the other server
During the start, GSCC recognizes that an HADR takeover has to be performed.
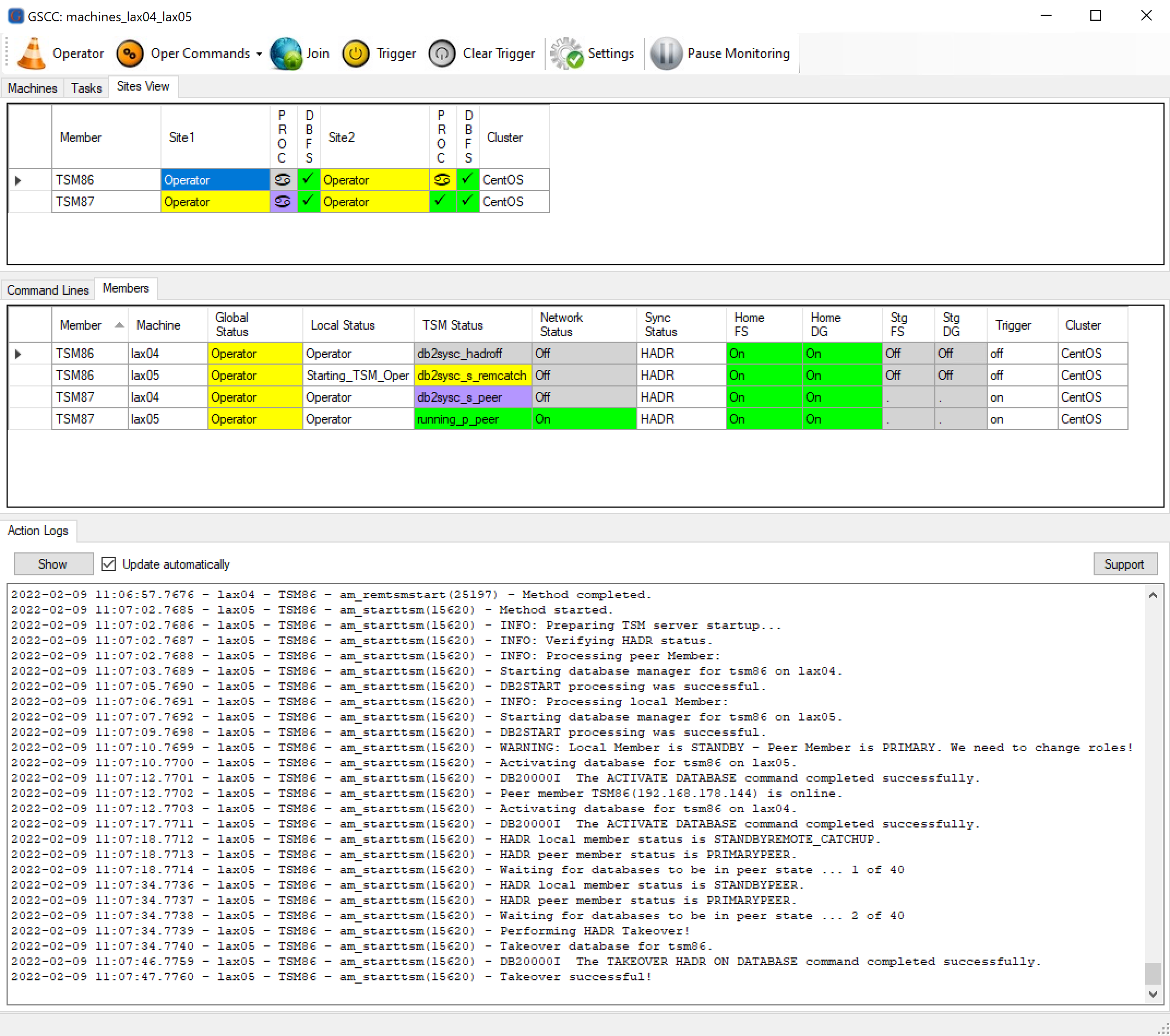
An HADR takeover will be executed
After a successful HADR takeover, the storage volumes are activated, ISP is started, and the service IP is configured on lax05.
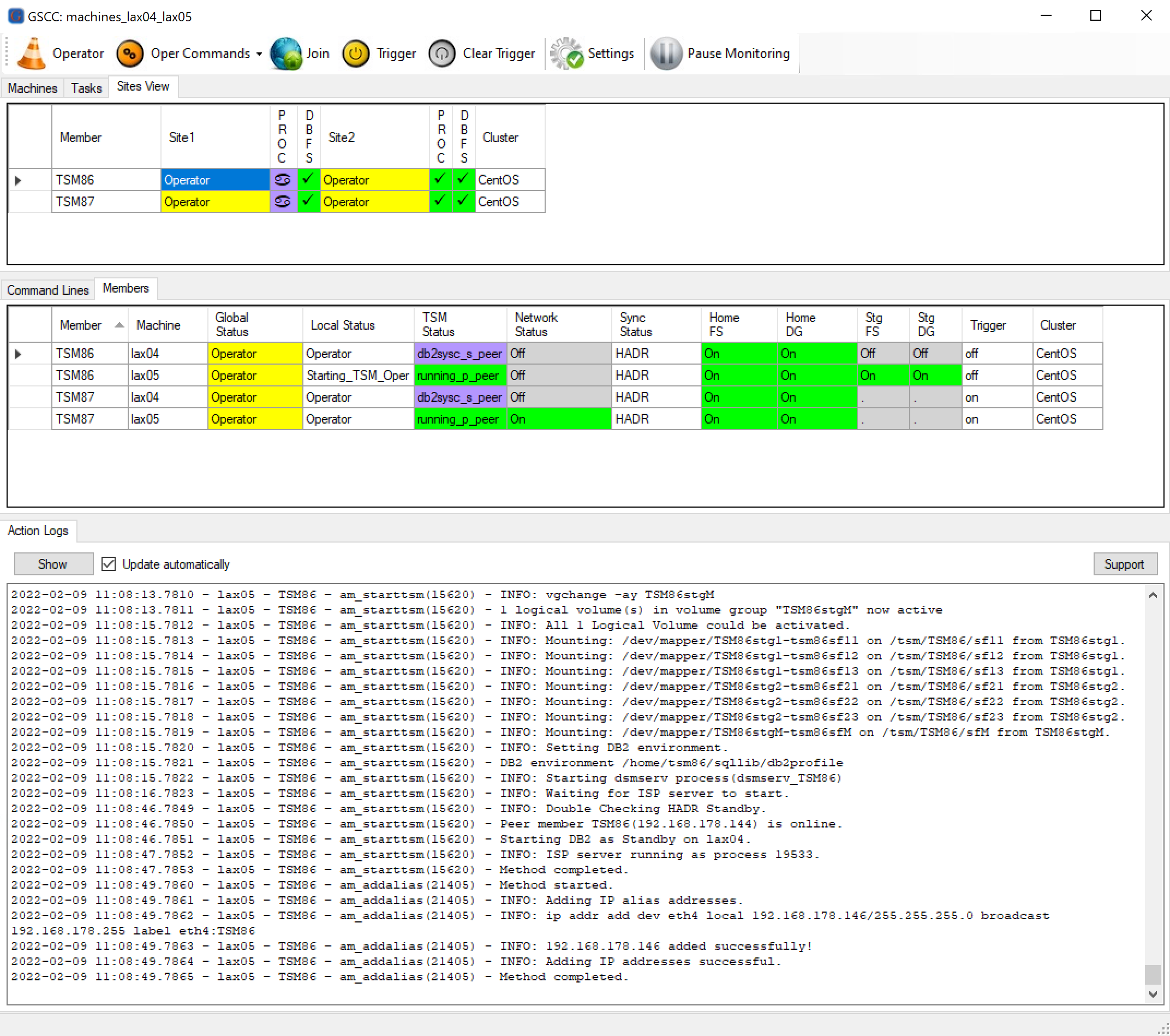
GSCC starts all resources and the ISP server on lax05
When the switch is done, GSCCAD will show that both members are in peer again, with changed roles.
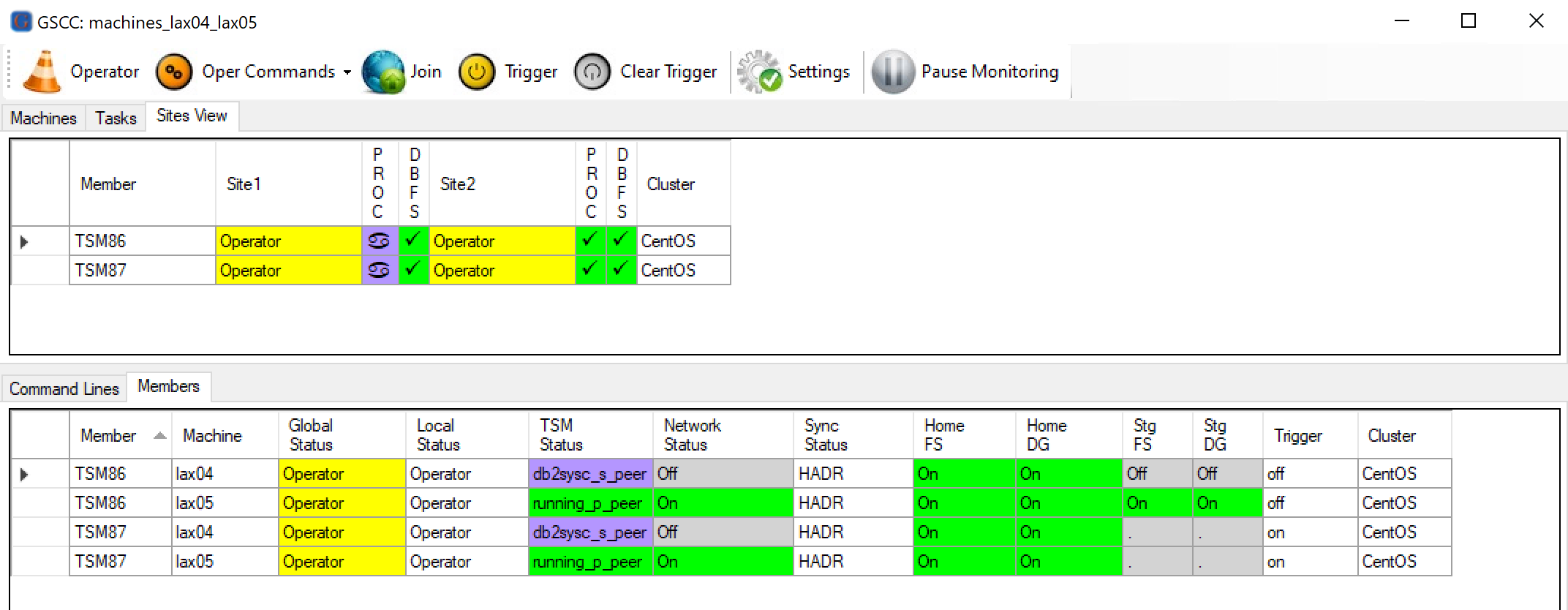
The switch is completed
IP - ISP Instance Restart
If the Spectrum Protect Server needs to be restarted to, for example, activate a configuration change, we can use the “Restart SP/TSM Services” option in GSCCAD.
First of all, let us enable Operator mode on the instance we want to restart.
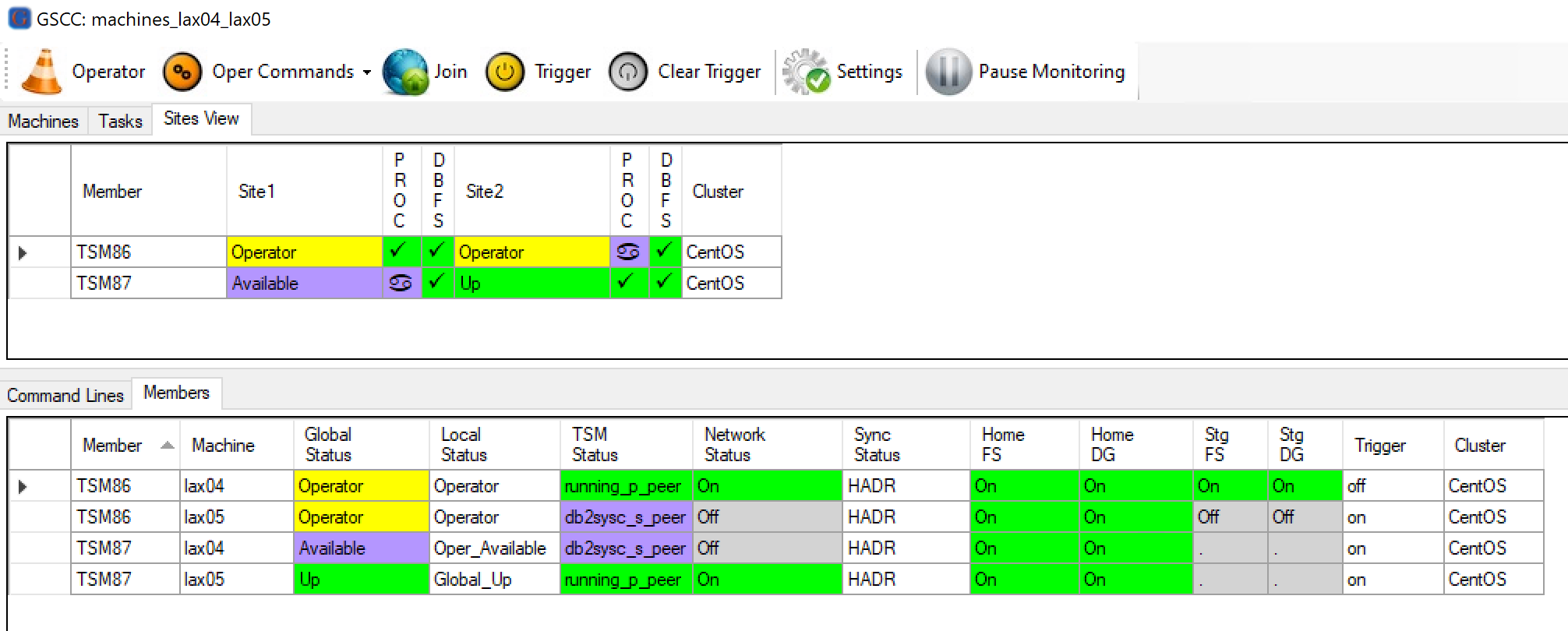
Make sure we are in Operator Mode
Now we select the member with the running ISP instance and select the “Restart SP/TSM Services” command.
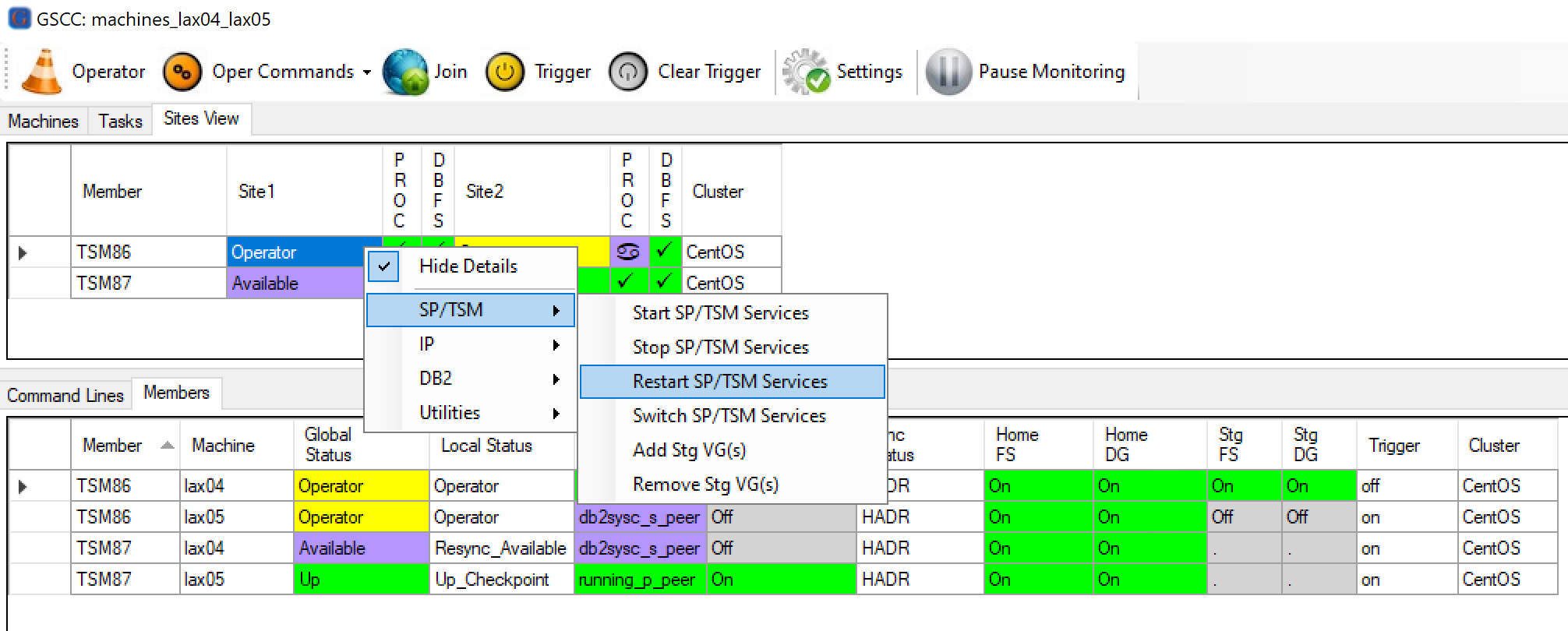
Selecting “Restart SP/TSM Services” from the members operator command menu.
A confirmation window will appear.
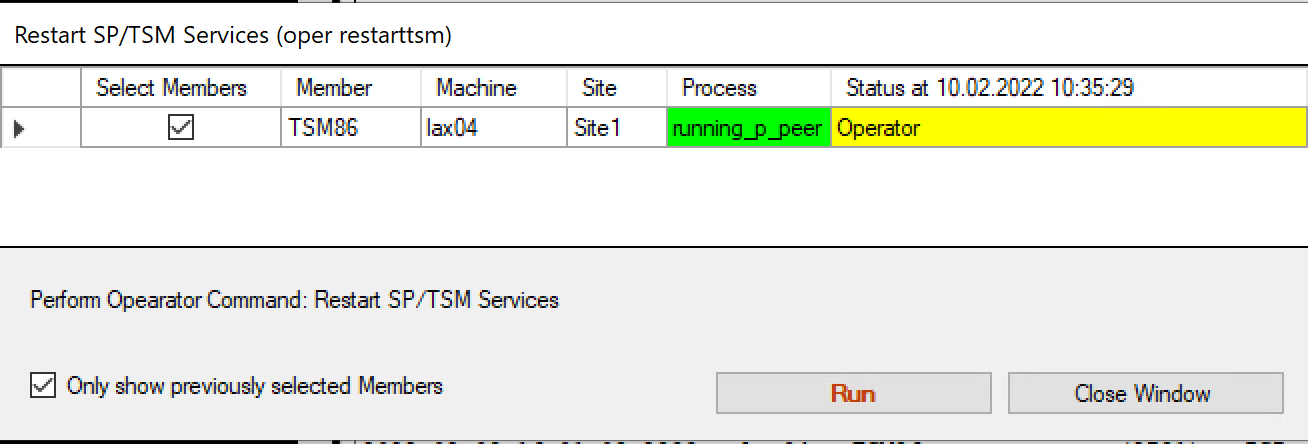
We need to confirm the restart with “Run”.
After confirmation, GSCC will perform a full “stop” procedure, meaning, that the service IP address and storage pool resources will also be deactivated if configured.
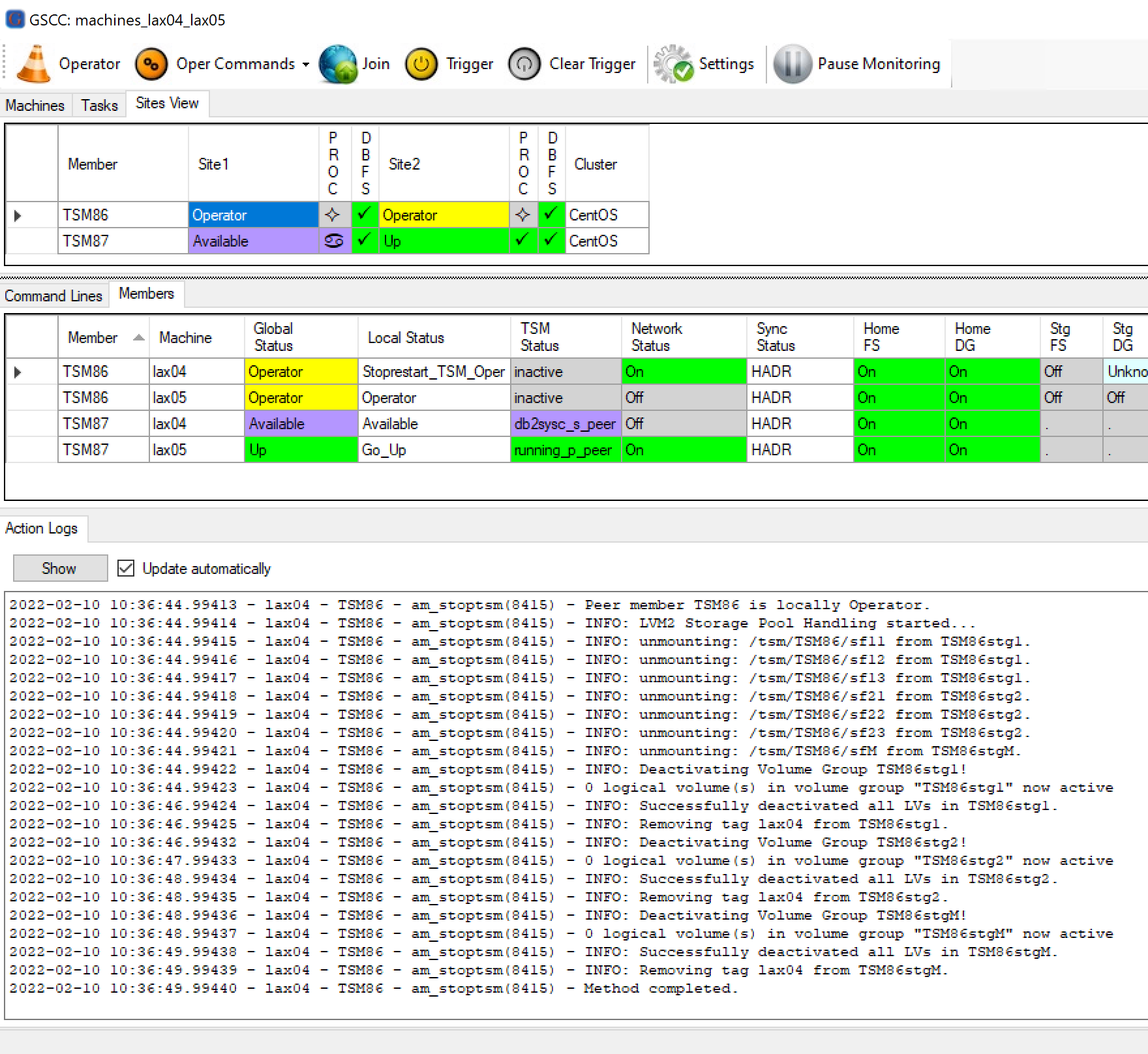
GSCC stops all the configured resources in addition to the Spectrum Protect server.
Immediately after the stop finished, the resources and the instance are brought up again.
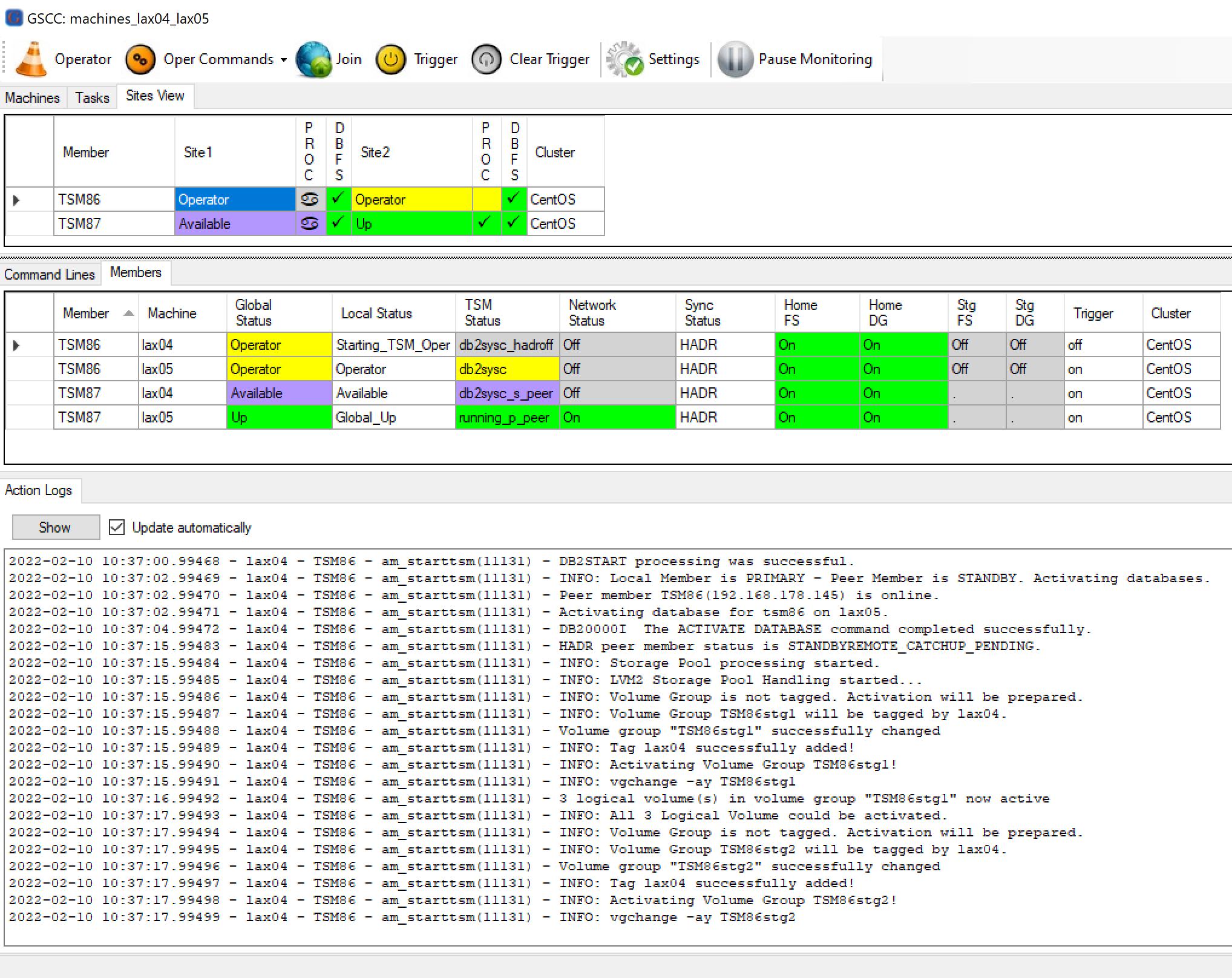
GSCC proceeds to start the DB, activates the volume group and so on…
If configured, GSCC will show the console output of the starting Spectrum Protect Instance.
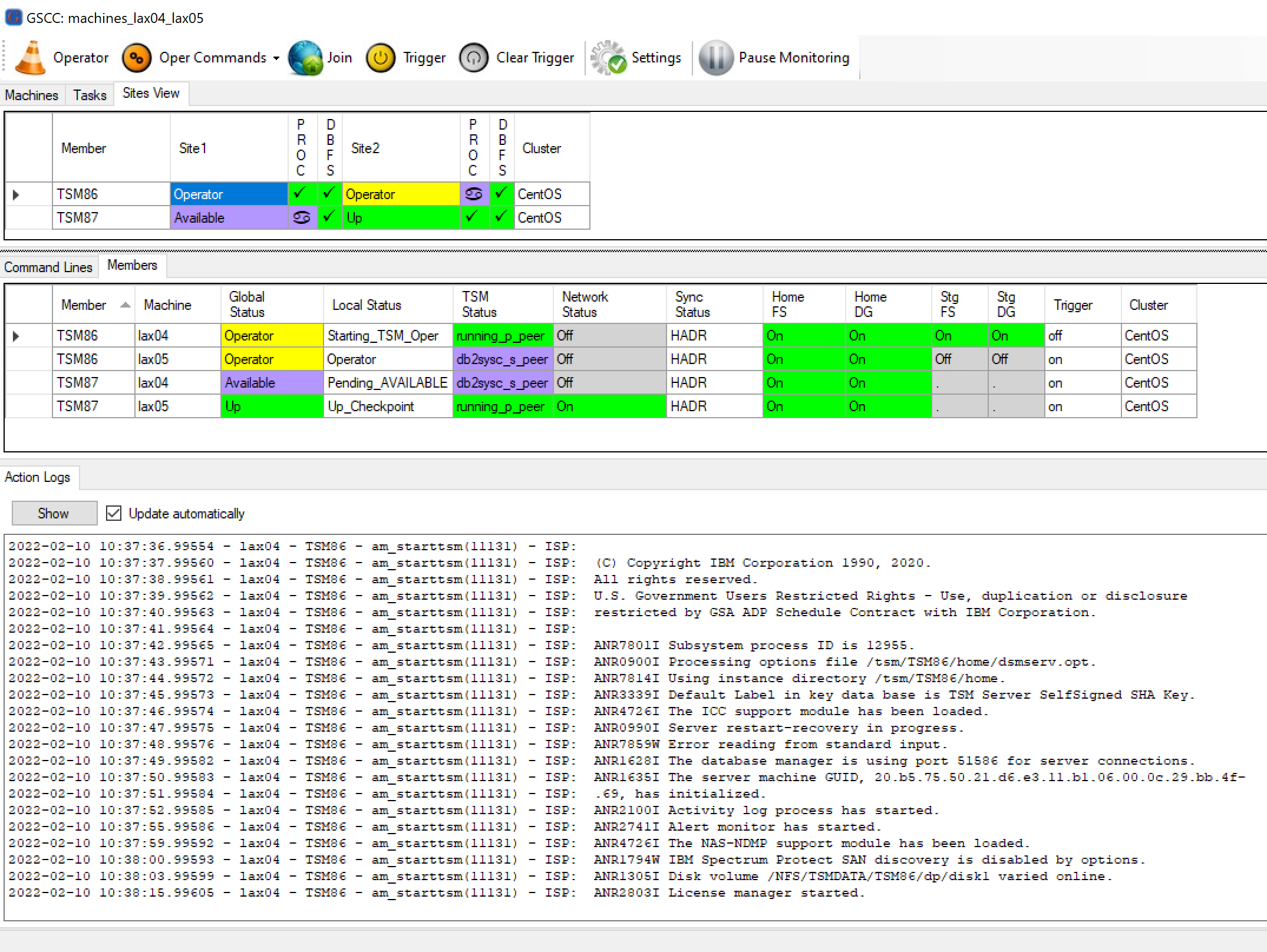
ISP Console output is shown in GSCC Action Logs
Finally the systems reach a peer state again after re-enabling the service ip address.
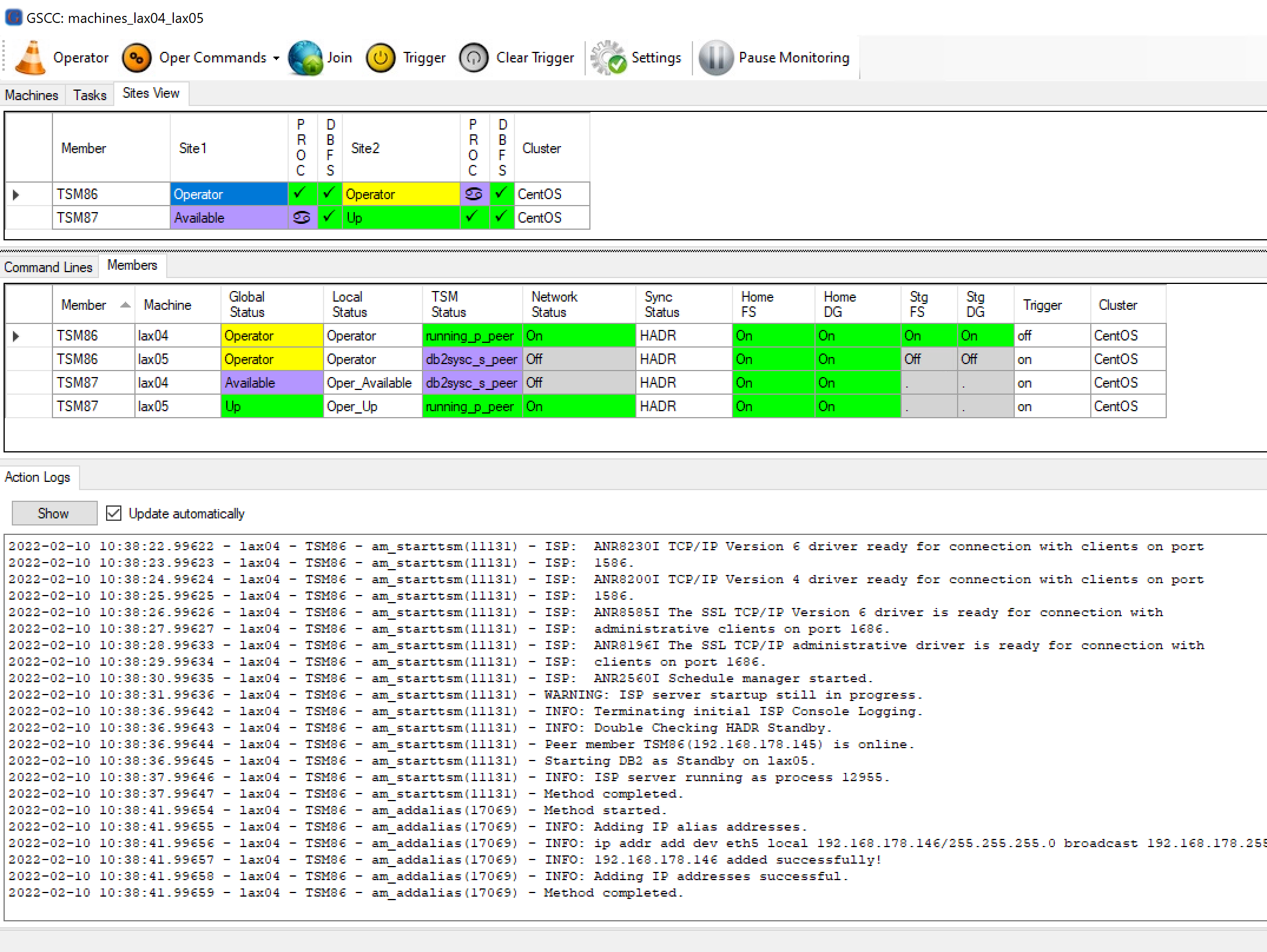
The restart is finished.
IP - Automatic Activation after Reboot
Usually the GSCC Operator commands are used to start and stop ISP. In a situation where both or one server node in the cluster were rebooted, it is also possible to just join the cluster to activate ISP. GSCC will consider the last HADR role in this case, so no takeover is required, but ISP is started on that server node, where it ran the last time. GSCC is in Operator Mode, all resources are offline. Only the LVM filesystems for the database are online, because they are local resources.
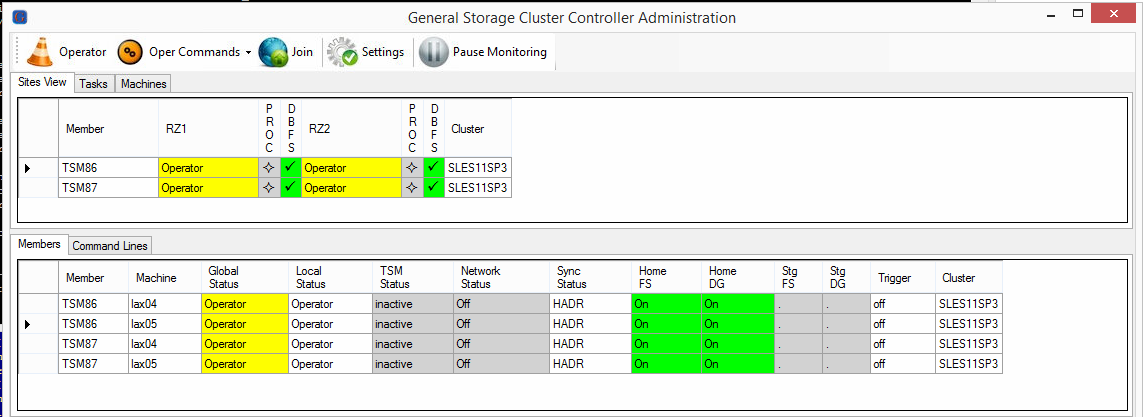
GSCC in Operator – Everything is down
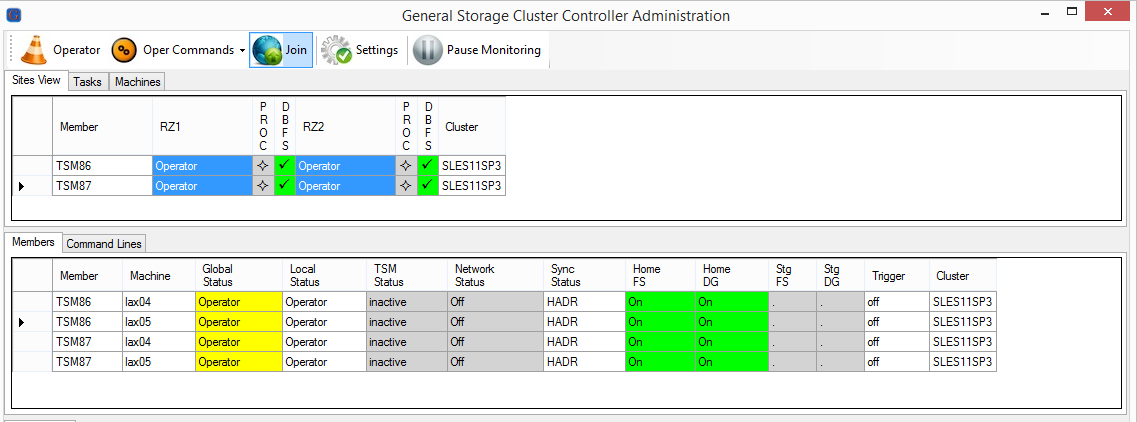
All Members selected
Executing “Join”
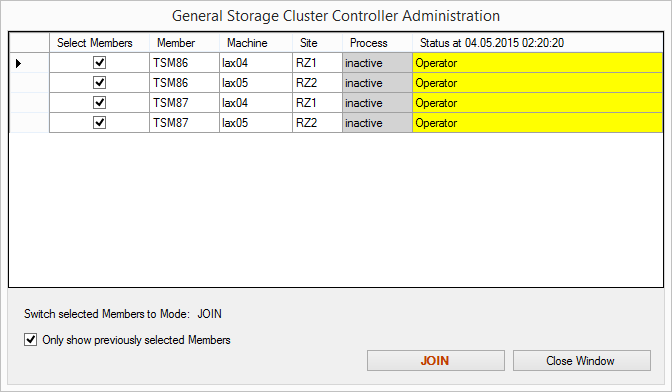
Confirm the “Join”
All Members are joining
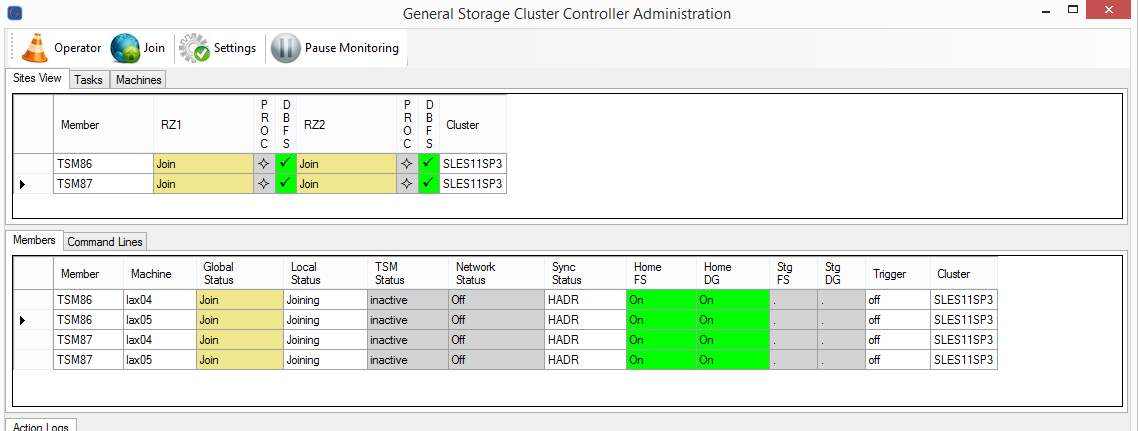
There are no resource online. That’s why all members are switching into the state “Down”.
All Members are “Down”
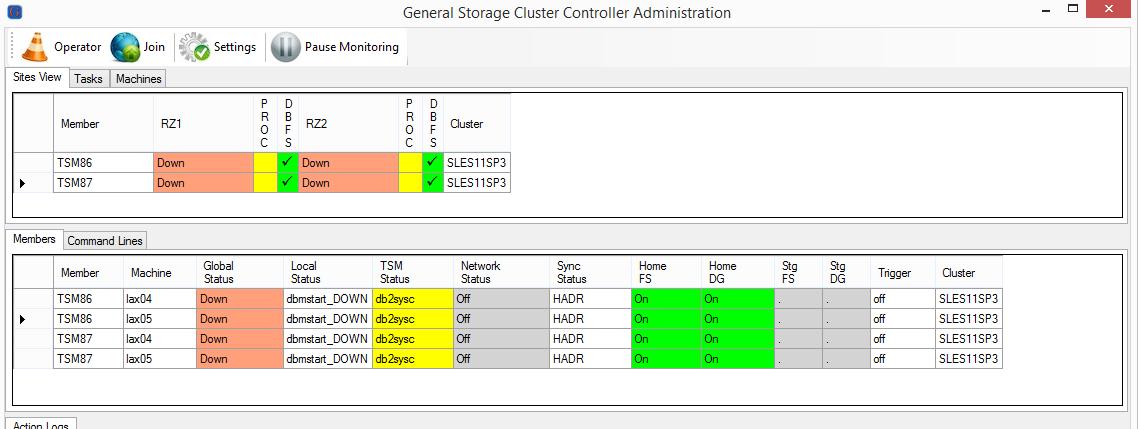
GSCC verifies the HADR roles and decides a state change to Up (primary) or Available (standby). The states will trigger the activities required to reach the expected status.
Roles verified
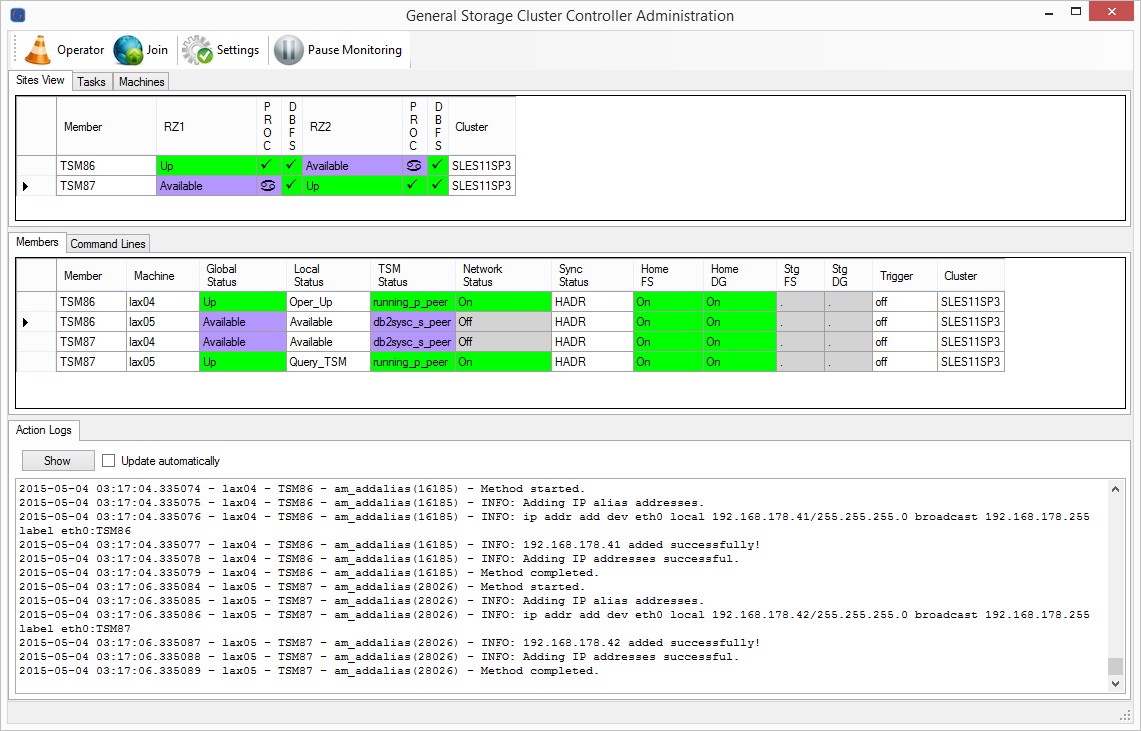
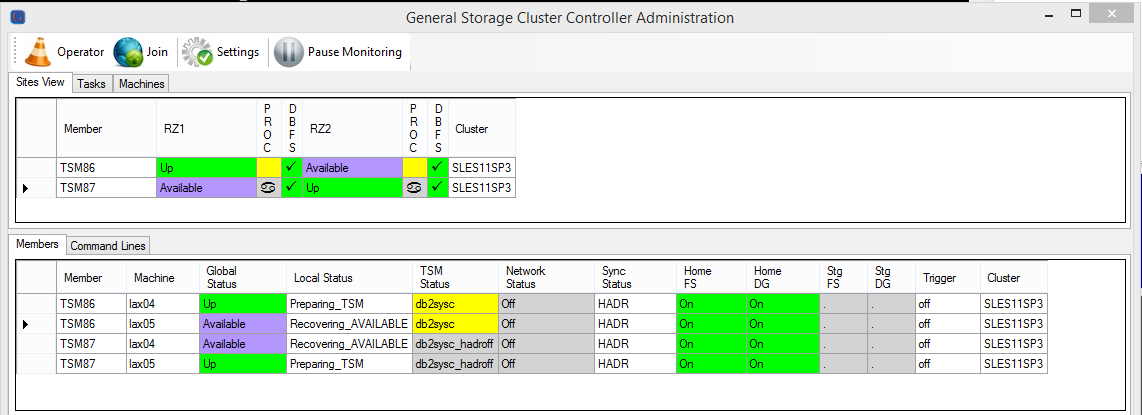
All Resources activated again
IP - System Crash – HADR Failover
When a complete system is down, a HADR failover is initiated. As the HADR communication is not available anymore, the failover needs to be forced. The client IP quorum needs to be met to allow the automatic failover to be started. In case the other system was not crashed, but isolated (not meeting the quorum) it will stop all activities and will not restart even if communication is re-established. To ensure consistency GSCC will only perform an HADR “force takeover in peer window only” on the surviving server. This HADR function will prevent the takeover, when before the failure the communication between the HADR nodes was already lost. In case of a split between the sites the primary can no longer ensure a synchronized state (“peer” state in HADR terms) with the standby. Therefore during the peer window no transaction will be For more information on HADR and peer window, see the IBM DB2 HADR documentation.
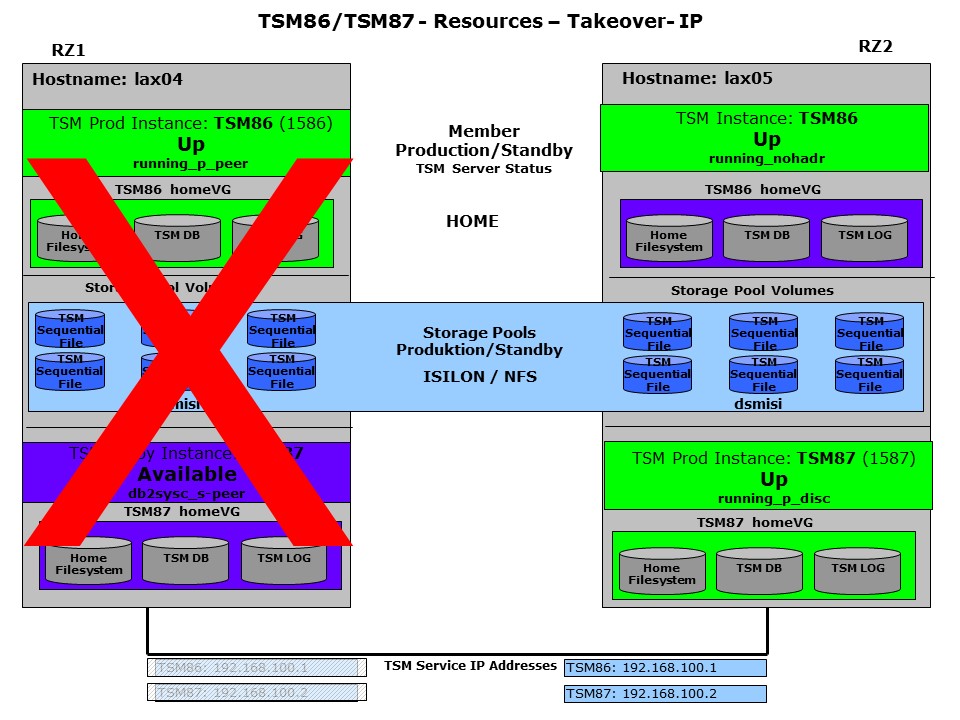
Server Crash
Before the crash the status is as following.
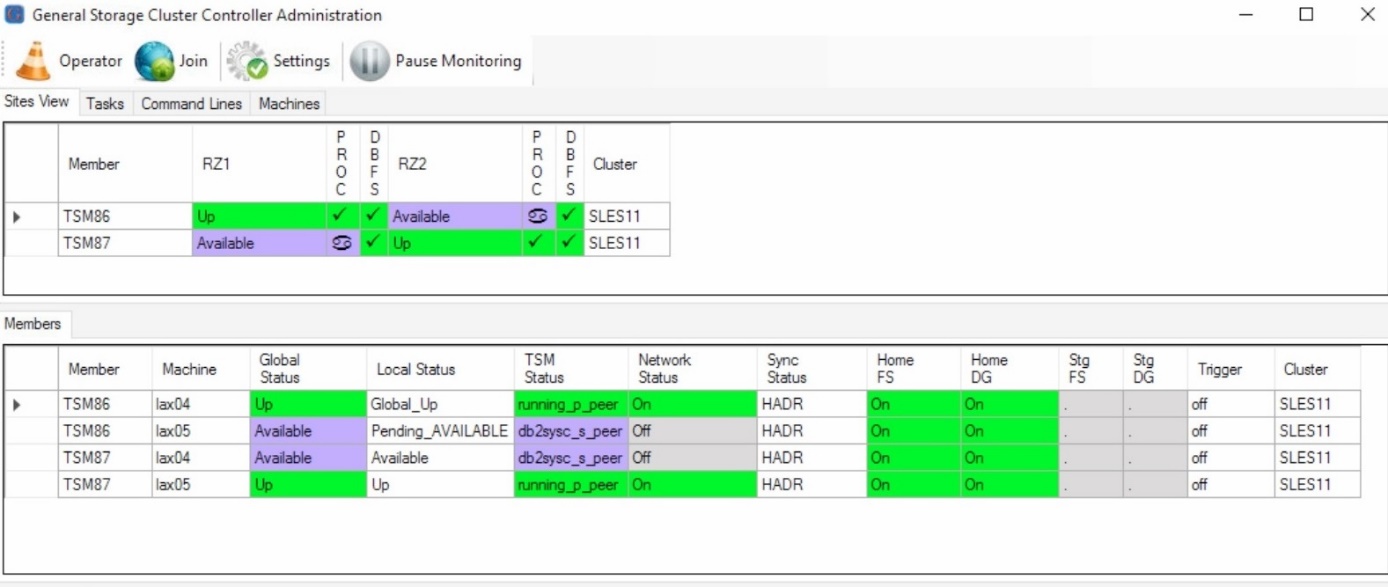
Normal Status
The physical server “lax04” has crashed. The status in “unknown”.
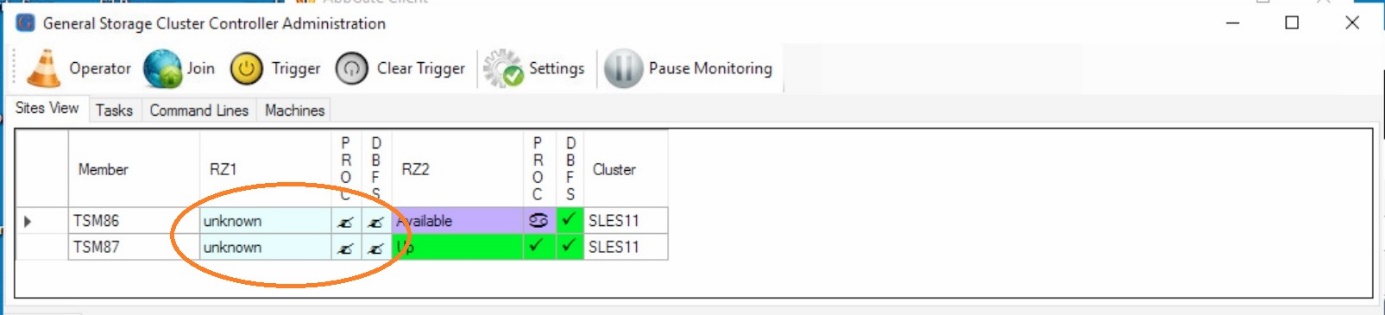
Server Crash
After checking the heartbeat and the client ip quorum, the decision is taken to takeover the database. This is visible by the member state switching to “Up”. The process state is still standby and needs to be changed.
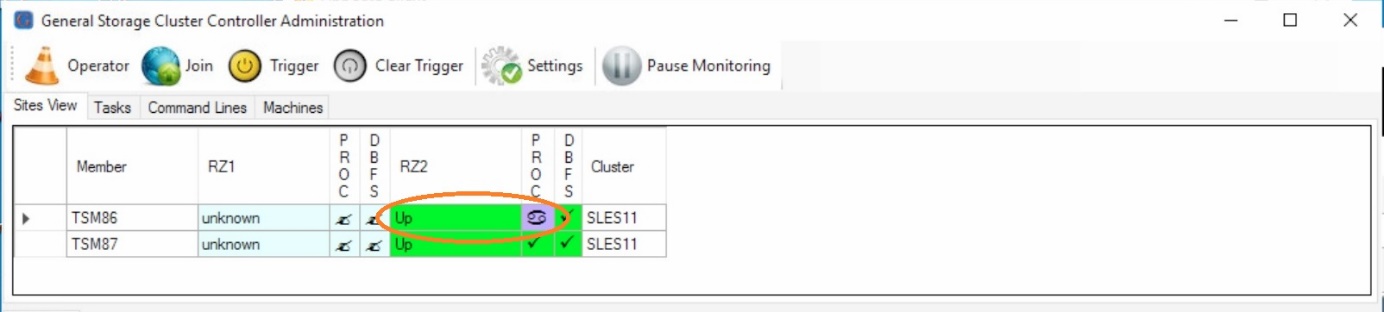
Cluster Reaction

Checking HADR Status
The log shows the final takeover command using the “peer window only” option to ensure consistency.
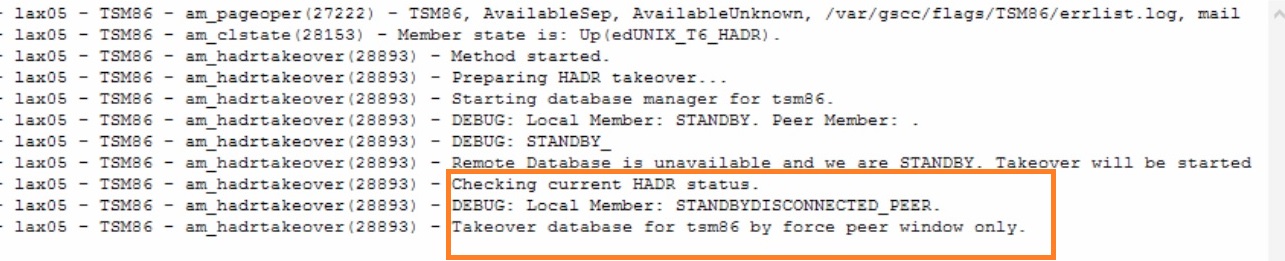
Takeover – peer window only
The takeover is successful and the ISP server start is prepared. It is required to stop HADR at this point to continue.

Takeover successful
Finally the ISP server is started. The previous primary cannot be activated anymore at this point of time without manual intervention. If the remote server was only temporarily down, the previous primary can be reintegrated to the active database.
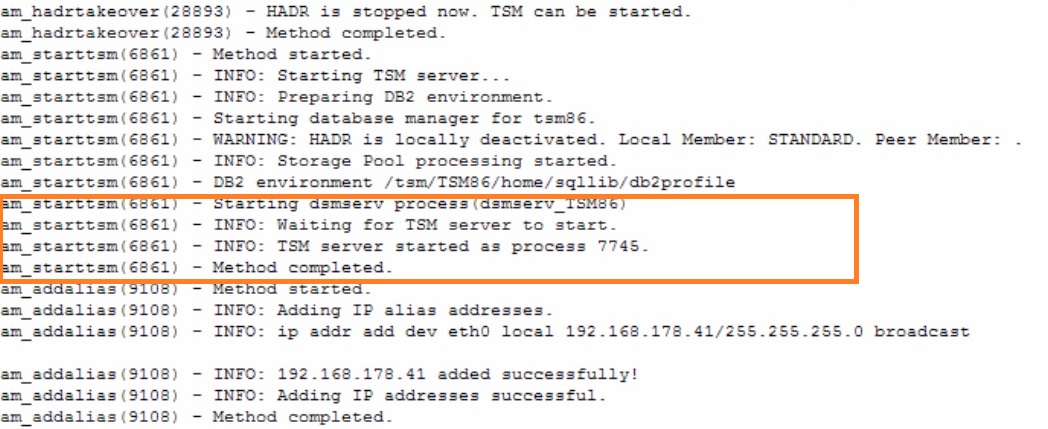
ISP is started
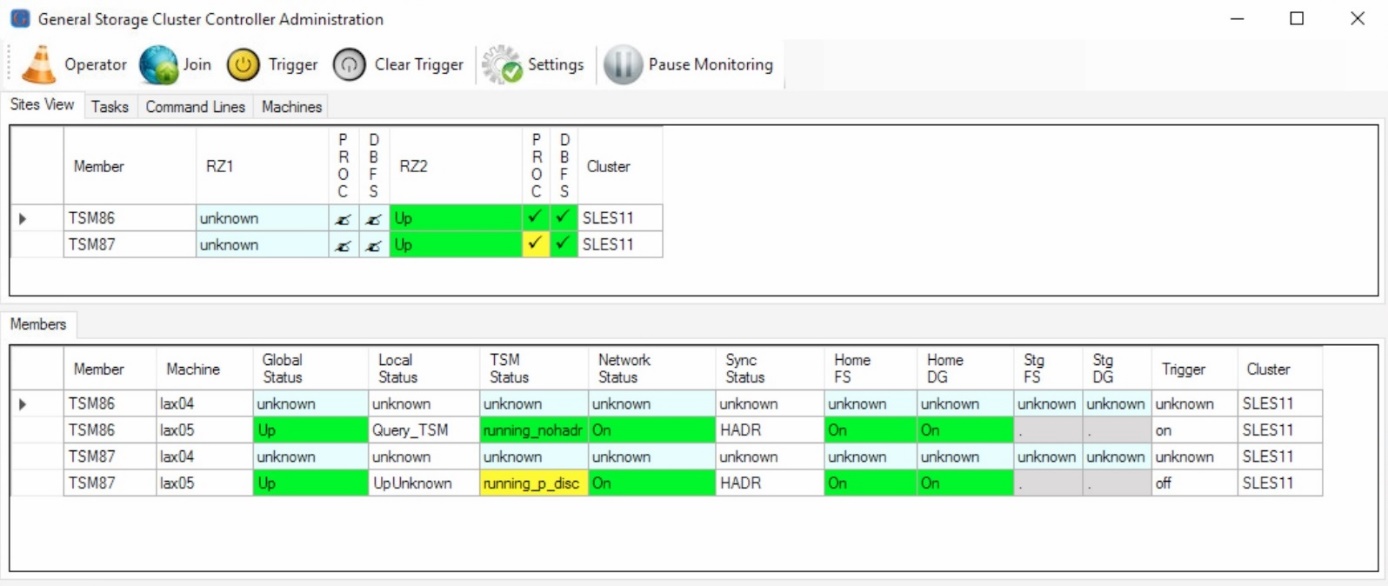
Both Instances running on lax05
DB2 Reintegrate after a Failover
After a system crash and a successful failover to the surviving node, cleanup steps will be required to reach a working HADR cluster status again.
In many cases, the databases on the crashed server were not affected, since the disks survived and only system needs to be restarted. In these situations it is most likely possible to activate the databases as HADR partner again.
In the documentation environment, there are two different cases, since two instances are part of the cluster:
TSM86: The database was the “primary” HADR partner before (ISP was affected and activated on the surviving node)
In this case the previous primary database must be “reintegrated” as the standby to establish redundancy again.
TSM87: The database was the “standby” HADR partner before (ISP was not affected and only the redundancy was lost)
In this case the standby database just needs to be activated again.
Is the system automatically restarted after the crash, GSCC would join the member after restarted and would attempt to perform the required activity. In cases where the node stays down and will be reactivated later, for example after repair actions, the tasks would need to be performed as Operator Commands.
Be aware that there are situations where GSCC and HADR cannot reuse the databases on the crashed server. Even with clean database disks the reintegration or standby activation can fail, especially if the required logs are already missing after database actvities or database backups.
This would require a database resync (db2 backup / db2 restore) to recover redundancy.
Automatic Cleanup
This is the GSCC status after the crash.
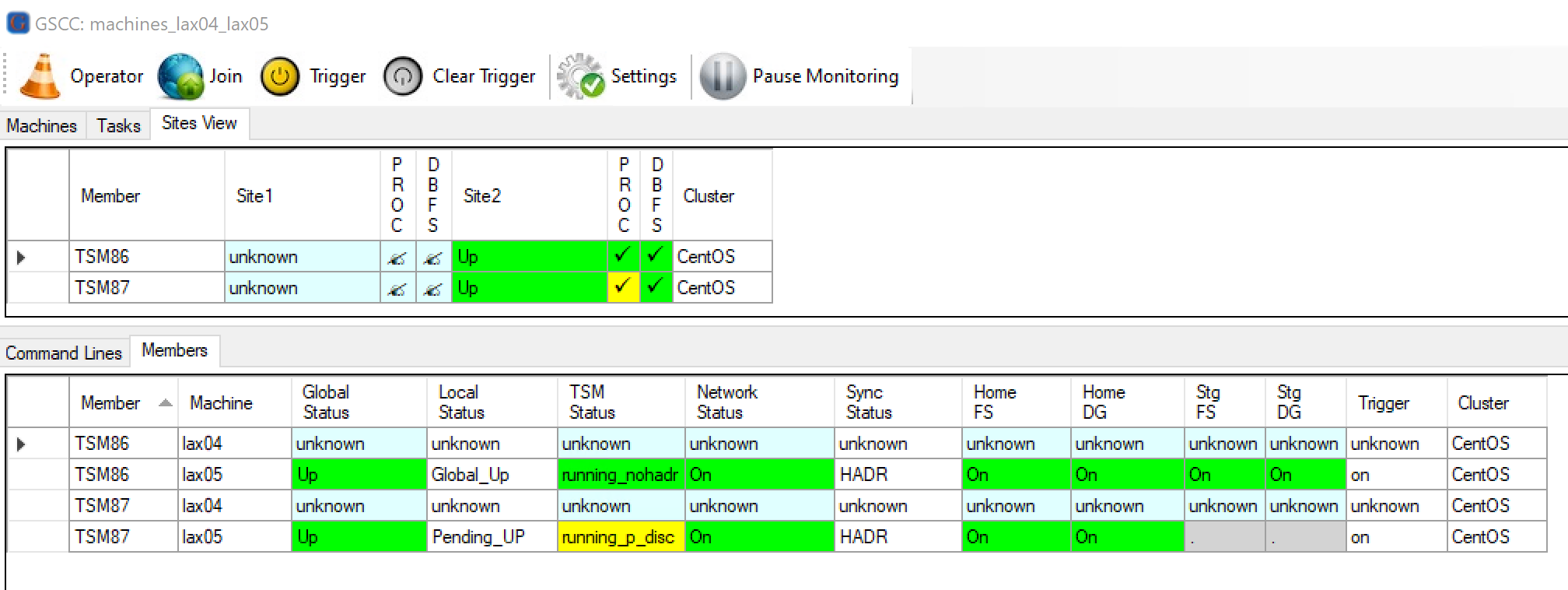
GSCCAD showing “unknown” status of the failed site
The crashed server is coming up again. GSCC is joining into the cluster.
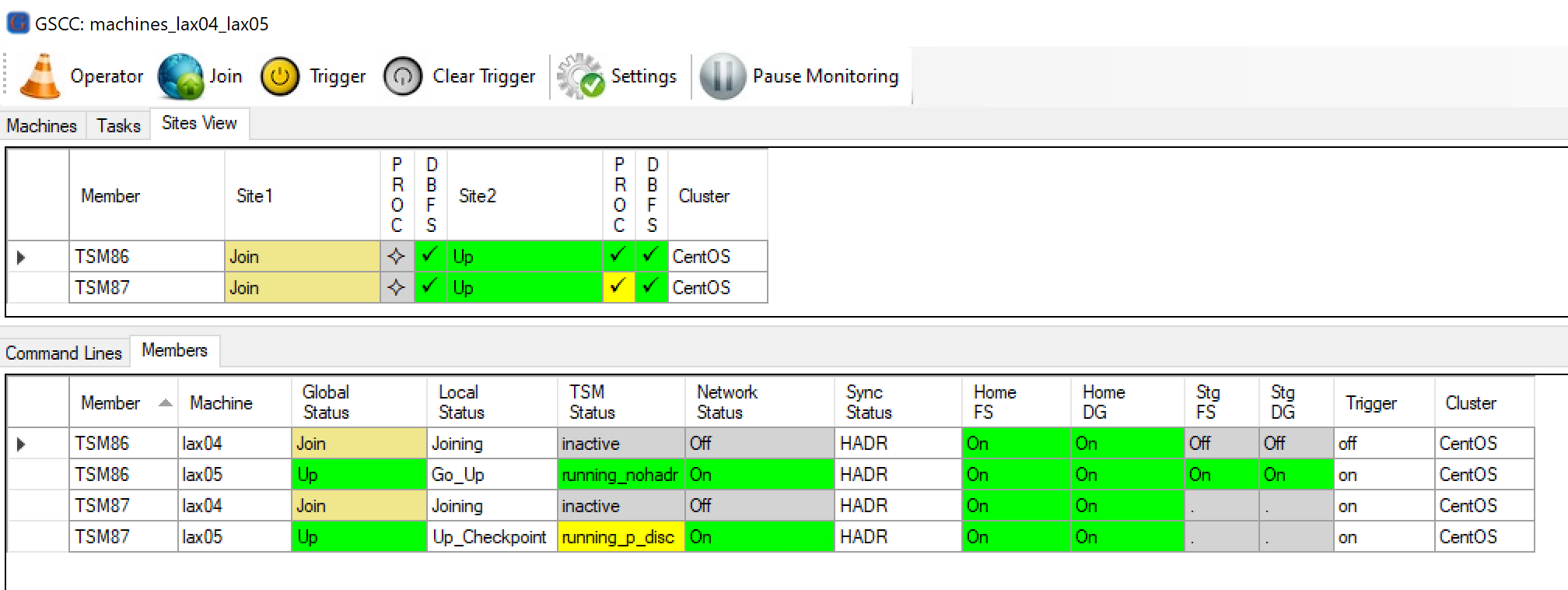
The failed site is up again and tries to “join” the cluster
Since no components are currently active both member switch to the “Down” state.
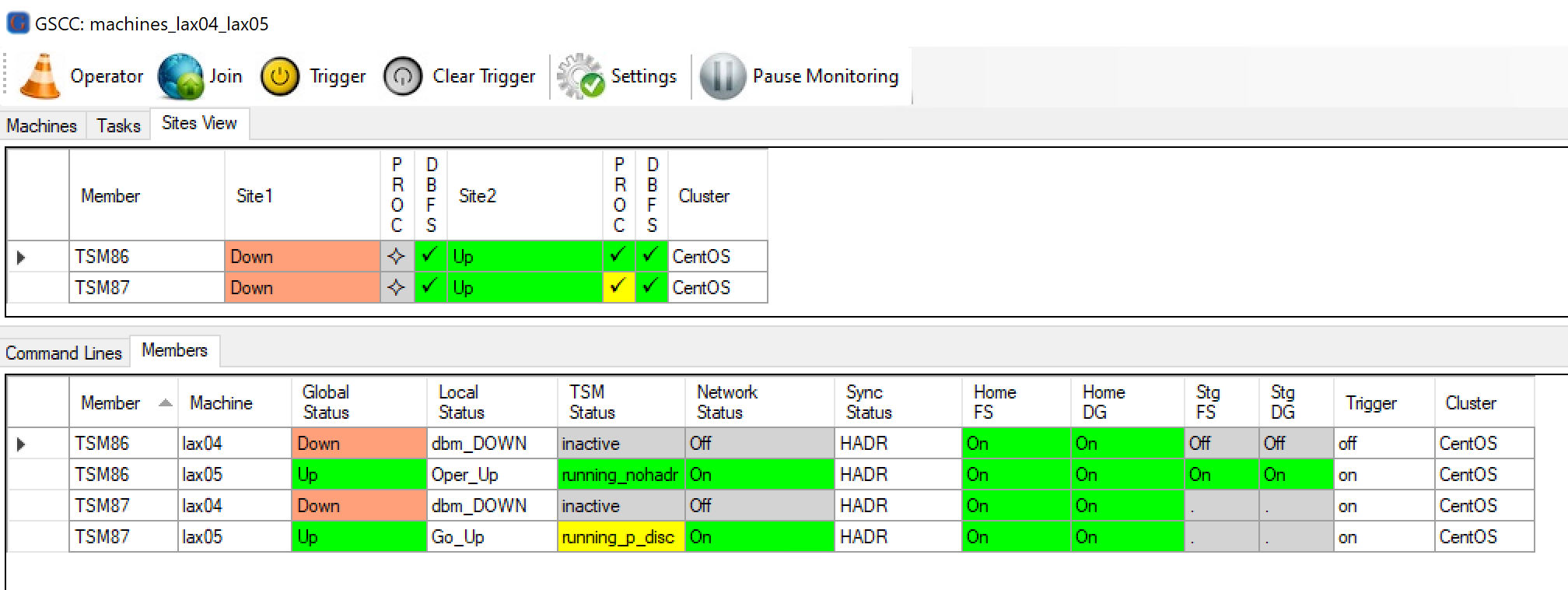
Since the site failed, at first both members will have the status “Down”
The remote members are “Up” and are controlling the ISP instances. Therefore the next state is “Available”, Where GSCC attempts to establish redundancy again.
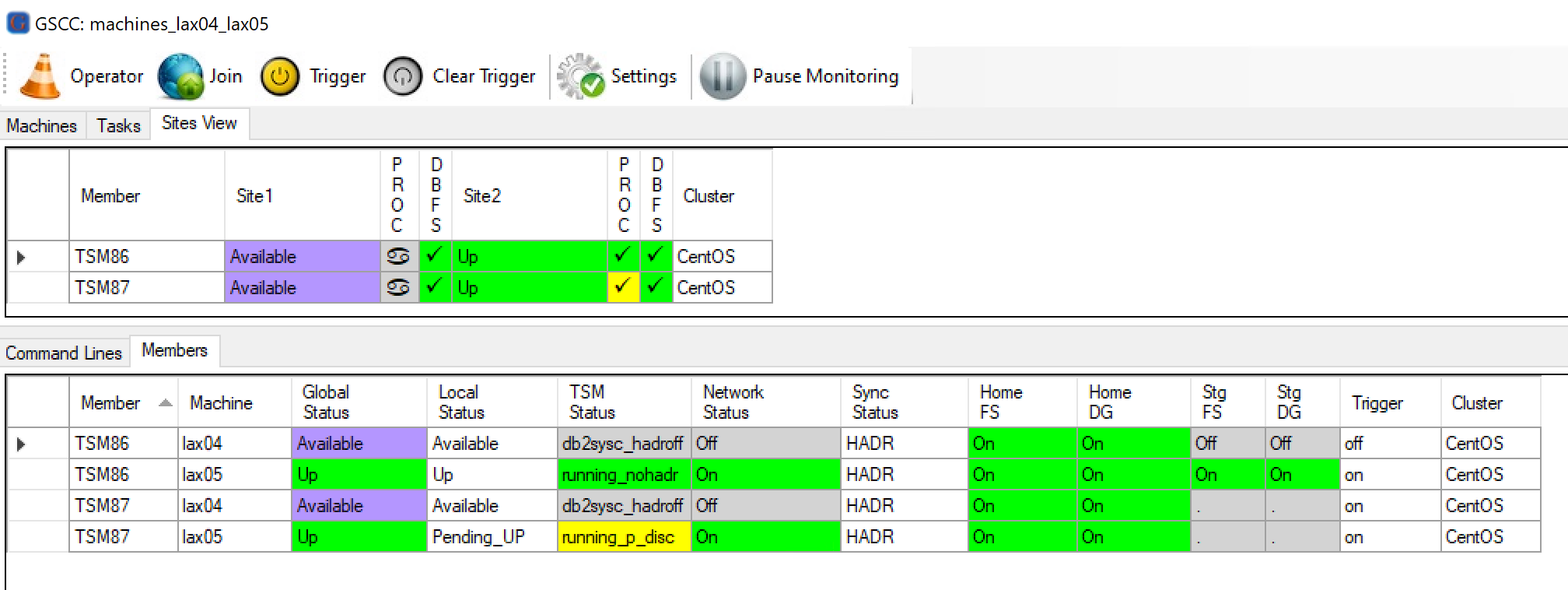
Both members were able to reach the “Available” status.
In order to establish redundancy for the two ISP instances the two “Available” members need to perform different tasks:
TSM86 was the primary before, therefore reintegration is started (am_hadrhealth)
TSM87 was even before the standby, so the database is only activated (am_hadrhealth)
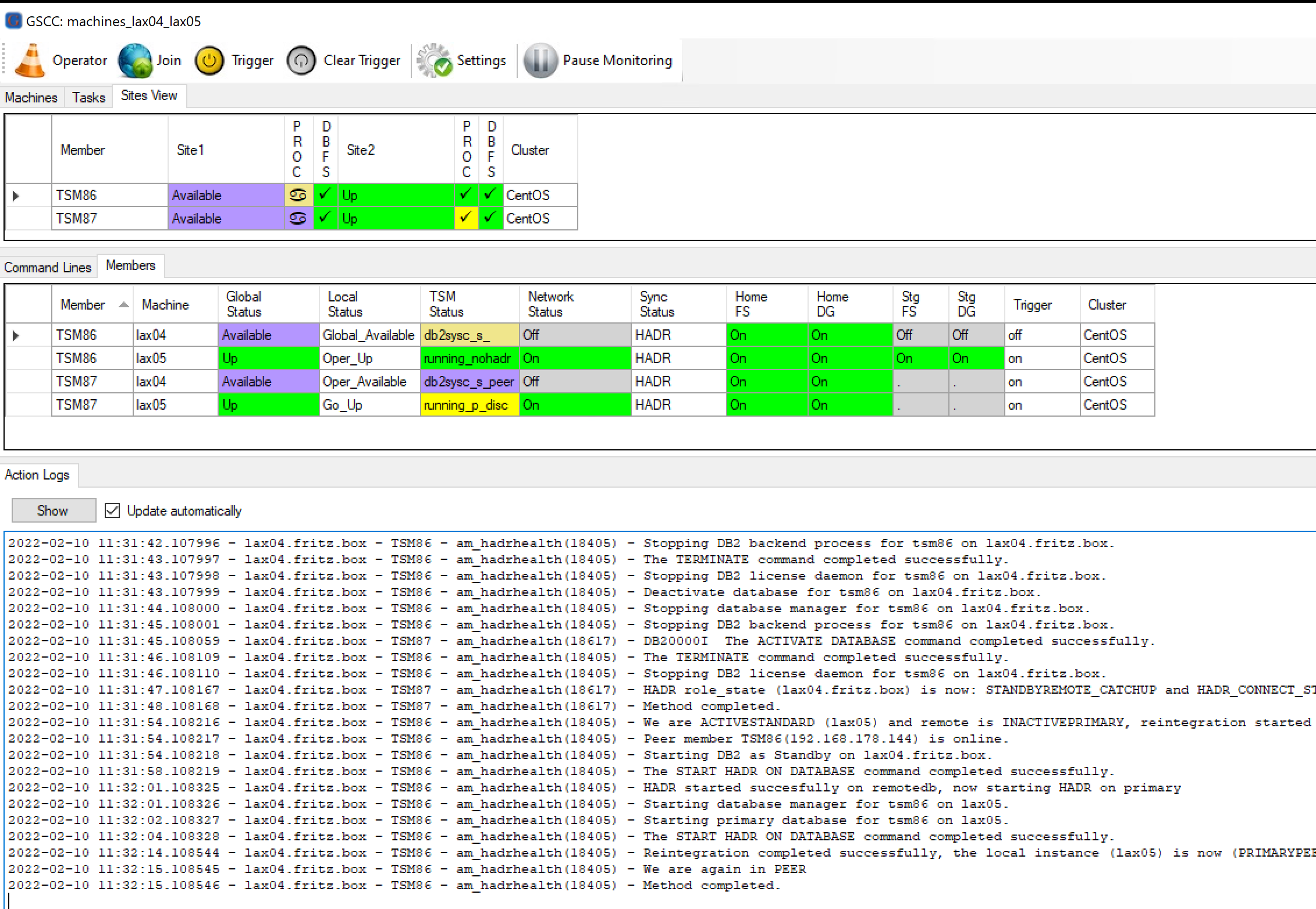
Action logs showing the performed methods.
The two databases of the previously crashed server were still in a good state. Since the server came up in time the required logs are still available and the reintegration and the standby activiation succeeded. HADR is in both cases in “peer” again.
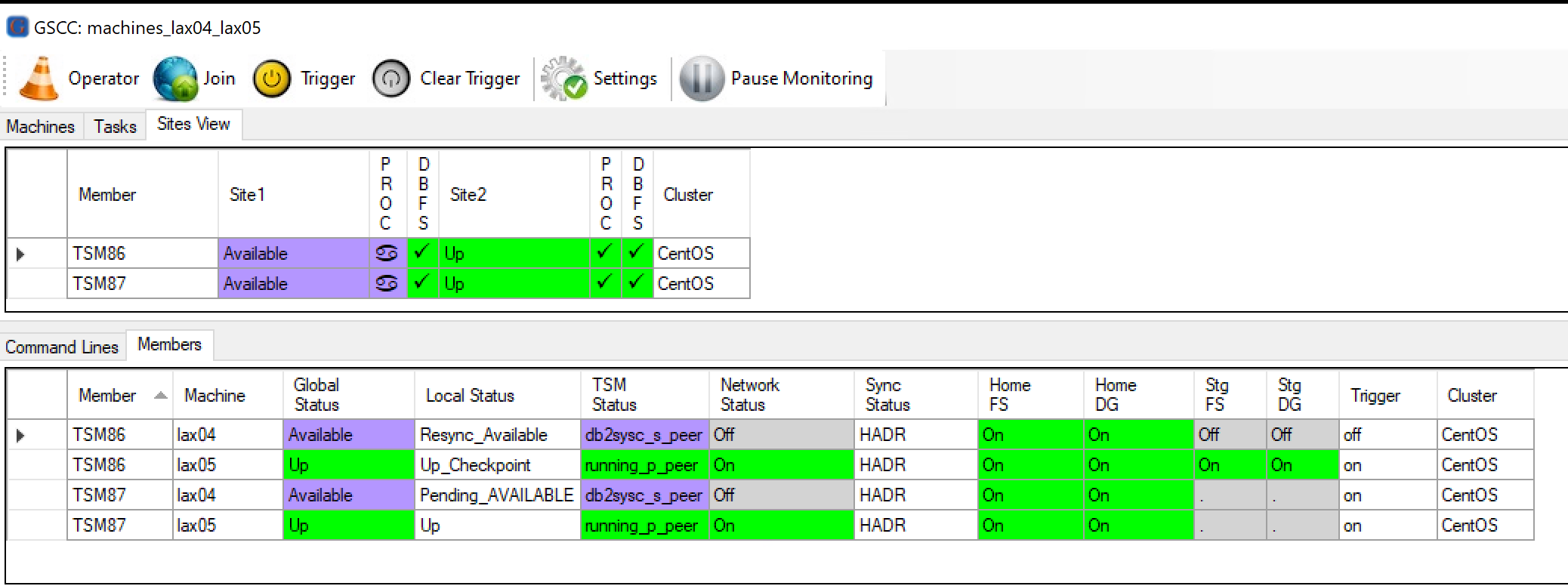
Everything is in “peer” status again.
Manual Cleanup
In contrast to the previous situation the previously crashed server could not be restarted immediately, so to cleanup the cluster we set it to Operator Mode.
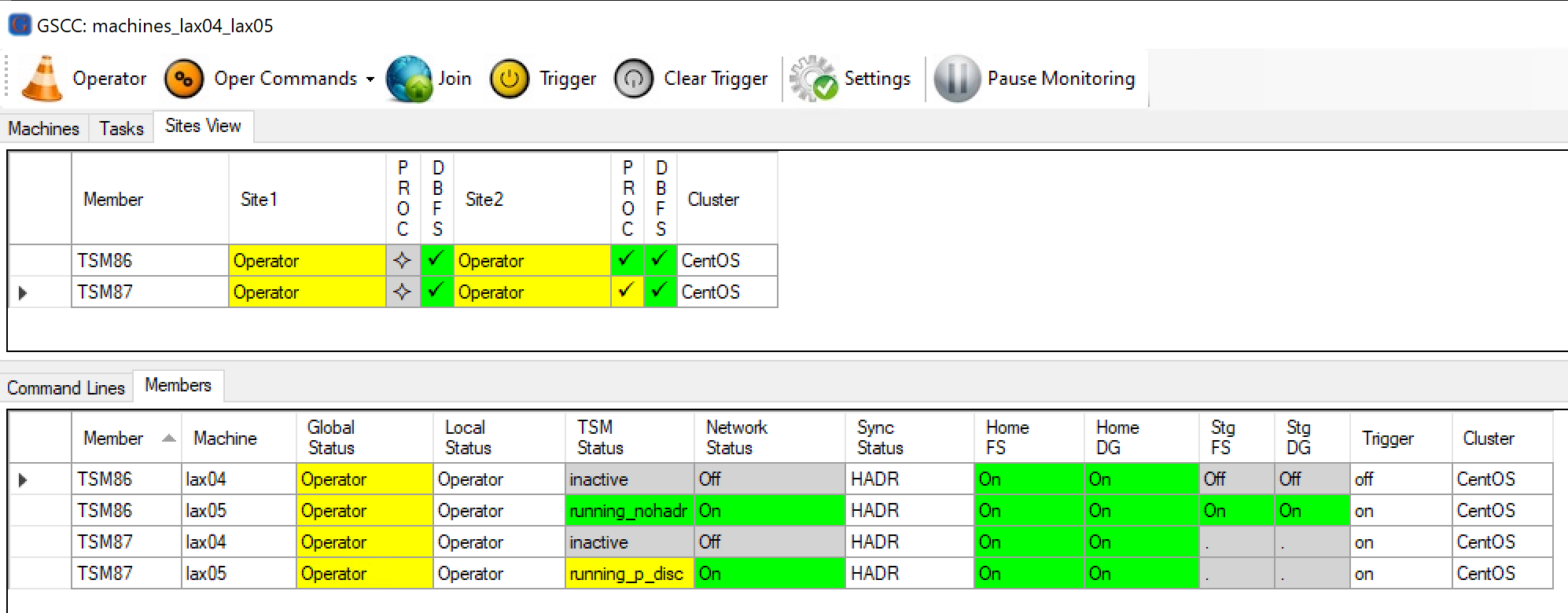
Cluster in operator mode
There are two different cases on the restarted node:
TSM86: The database was the “primary” HADR partner before (ISP was affected and activated on the surviving node)
In this case the previous primary database must be “reintegrated” as the standby to establish redundancy again.
TSM87: The database was the “standby” HADR partner before (ISP was not affected and only the redundancy was lost)
In this case the standby database just needs to be activated again
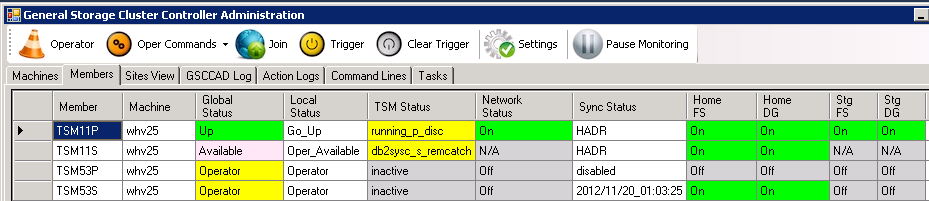
The two cases need to be performed manually now. The “Members” tab in GSCCAD allows to distinguish the cases by checking the “TSM Status” column.
TSM86: running_nohadr
TSM86: running_p_disc
Case 1: Manual Reinitegration (TSM86)
The primary member with the running ISP instance is selected. The Operator Command “reintegratedb” is in the Utilities menu.
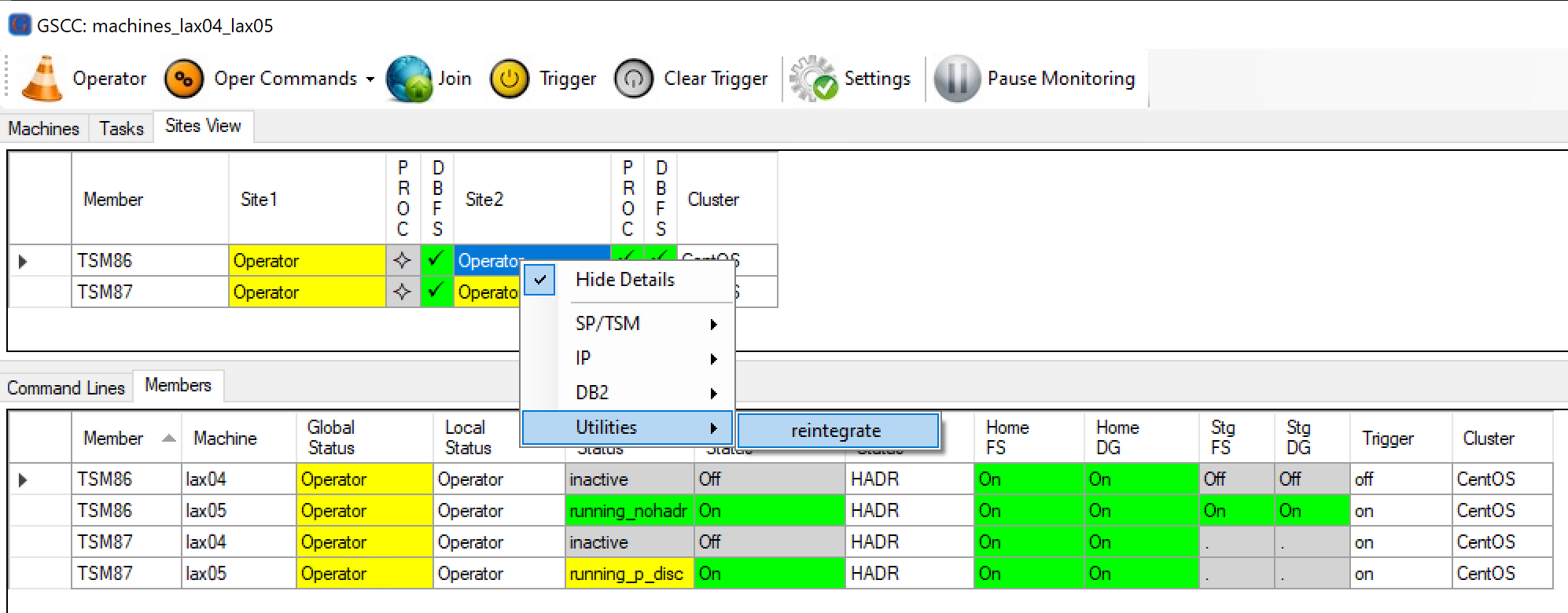
Using the “reintegrate” utility in GSCCAD
The confirmation window appears and describes the required conditions, which will be verified by GSCC before execution.
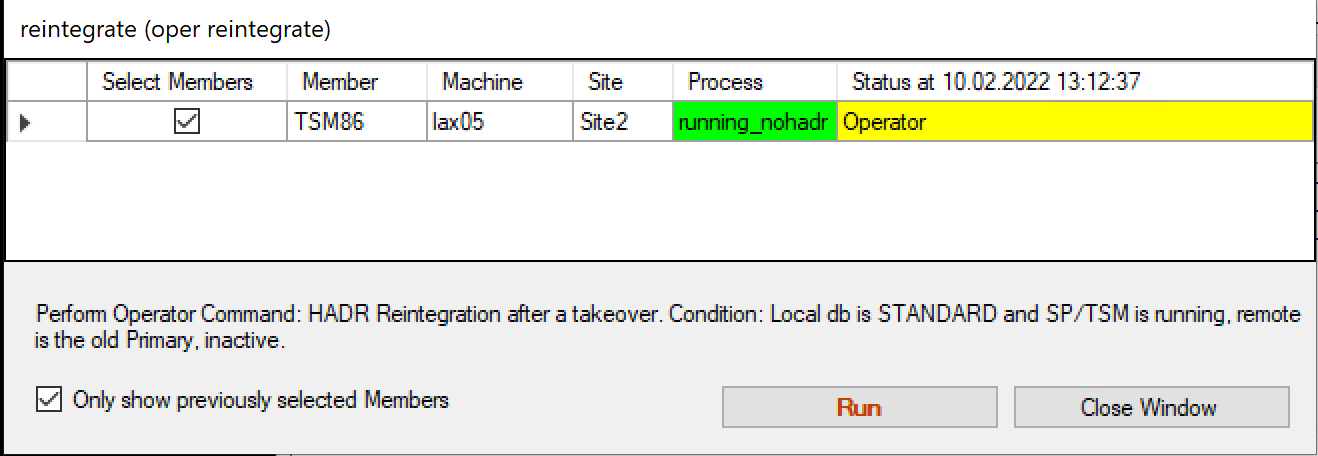
Confirmation window for reintegration.
In the “Action Logs” tab the reintegration task can be monitored. Depending on the number of required logs, the reintegration might not complete immediately like in this example. In such a case a message will be written to the log asking the Operator to check the HADR status.
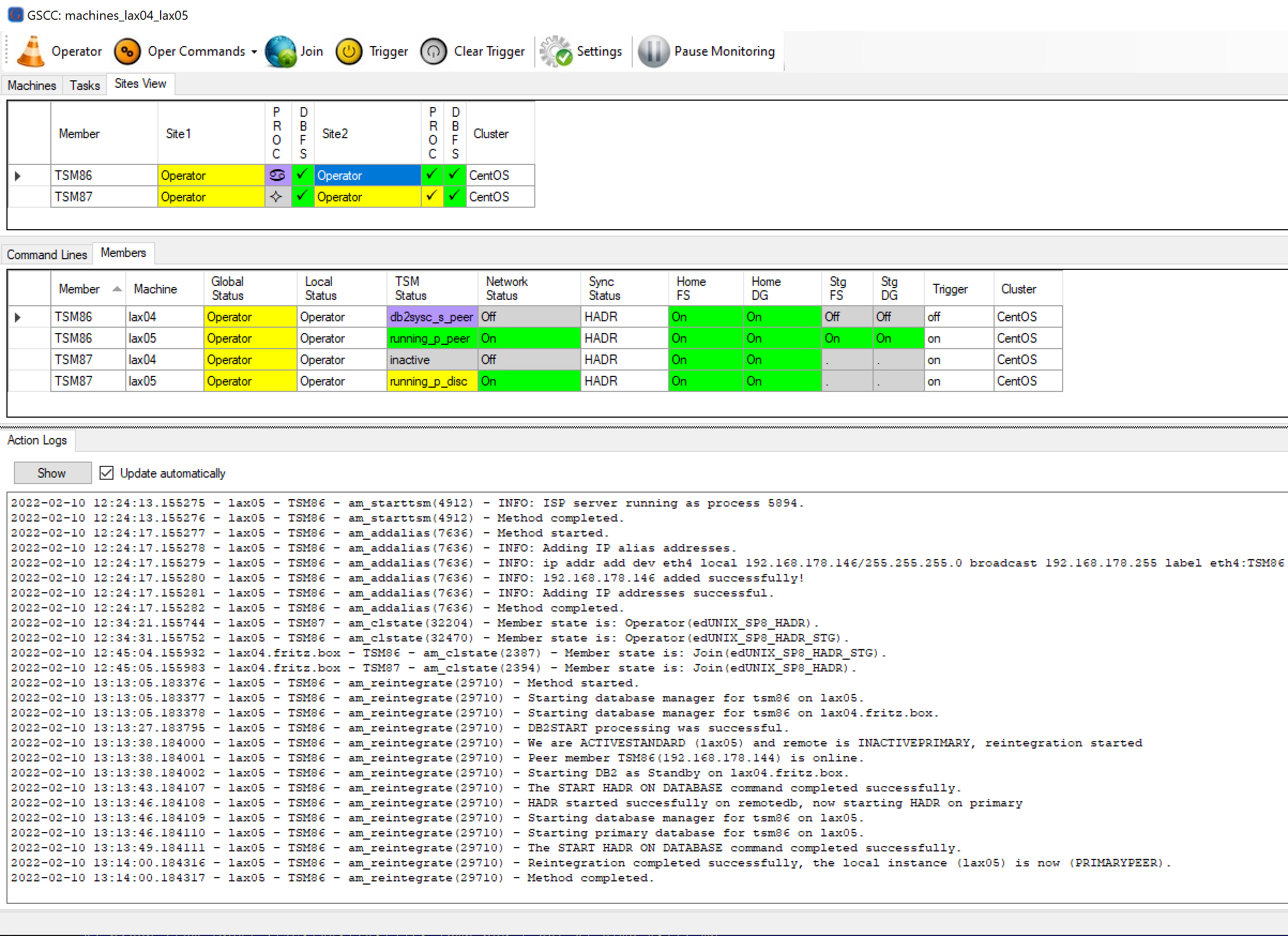
Action logs showing the performed methods.
Case 2: Manual Standby Activation (TSM87)
In this case the previous standby member needs to be activated. So the standby member is selected and in the DB2 menu the “StartStandby” command is used.
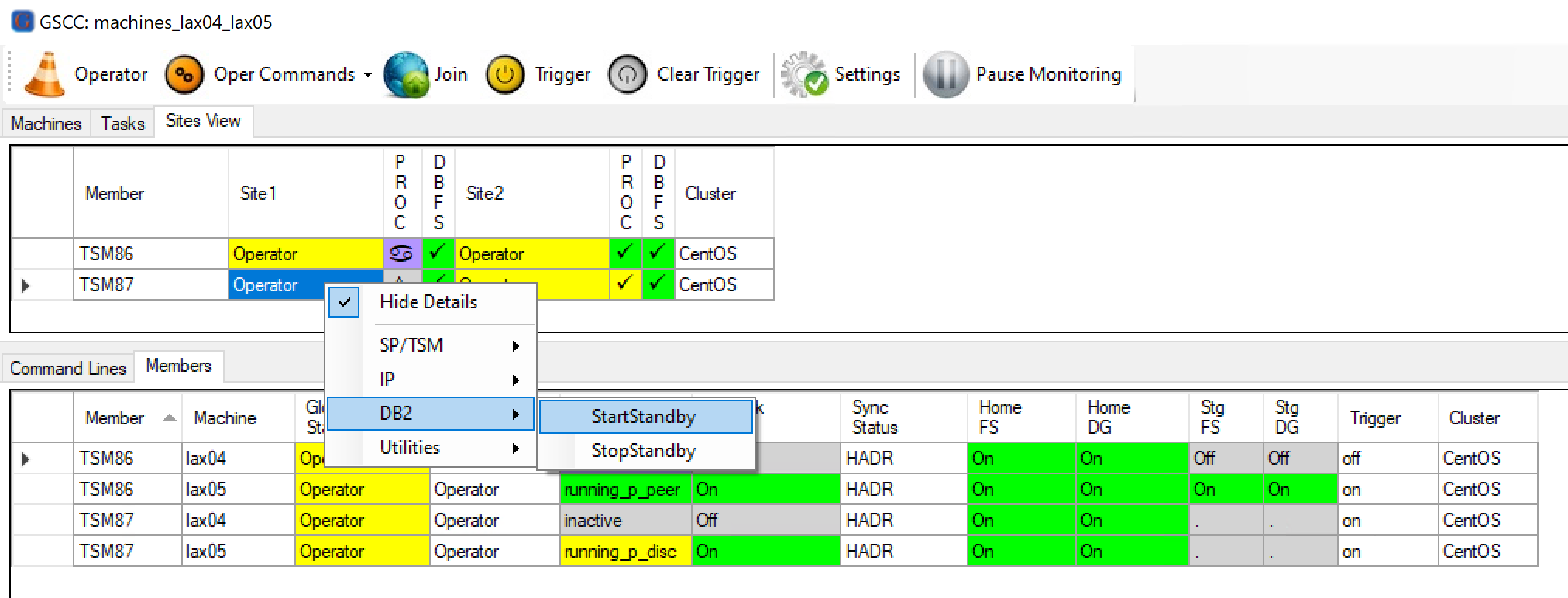
Starting the standby database
The confirmation window appears showing the inactive DB instance.
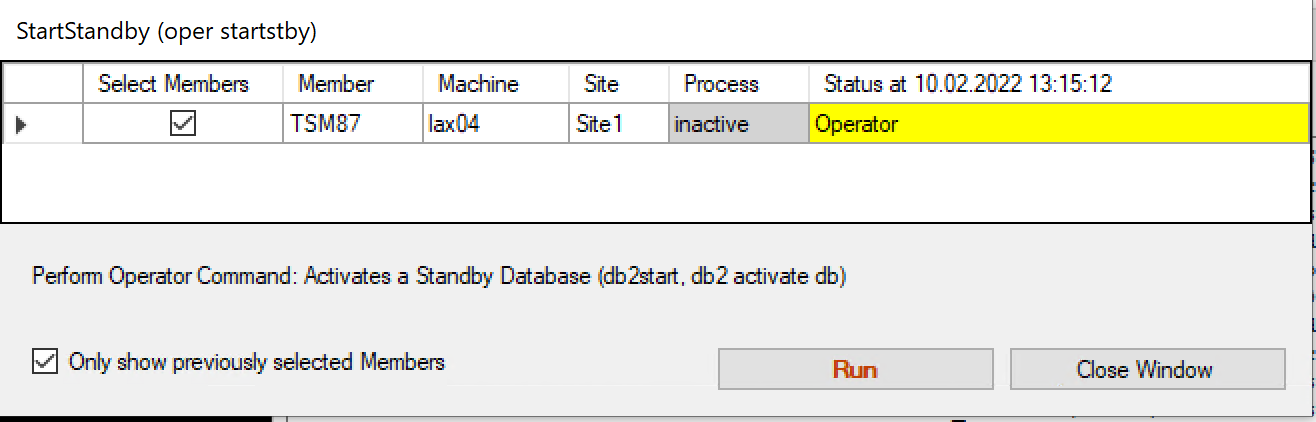
Confirmation for “StartStandby”
In the “Action Logs” Tab the command can be monitored. In this example the HADR status switched Shortly after the initiation into “peer”. However, this might take longer depending on the required logs to be processed.
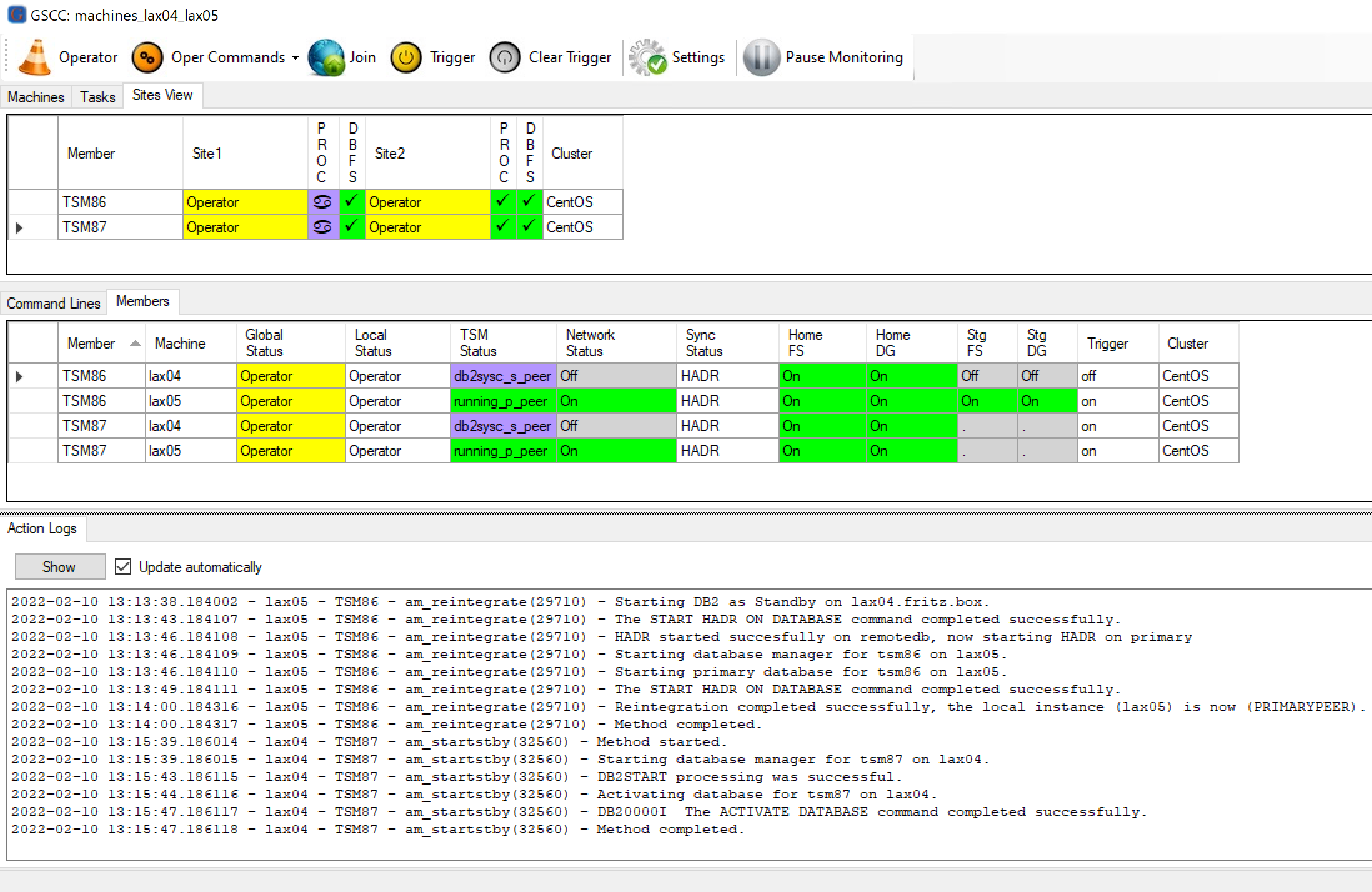
Action Logs showing the starting method